http
2021-02-28
HTTP概述 #
- HTTP是一种client-server协议,由客户端发出的消息叫request,被服务端响应的消息叫response。
HTTP能控制什么 #
一、缓存 #
- 常见的HTTP缓存只能存储GET响应。缓存的关键主要包括request method和目标url。
缓存控制(HTTP/1.1定义的Cache-Control) #
Cache-Control:no-store:没有缓存。缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。Cache-Control:no-cache:缓存但重新验证。此方式下,每次有关请求发出时,该请求会带有与本缓存相关的验证字段,服务端会验证请求中所描述的缓存是否过期,如未过期(返回状态码304),则使用本地缓存副本。Cache-Control:private|Cache-Control:public:私有和公共缓存。private表示该响应是专用于某个用户的,中间人不能缓存此响应;public表示该缓存可以被任何中间人缓存。Cache-Control:max-age=31536000:过期。表示资源能被缓存的最大时间,max-age是距离请求发起的时间的秒数。Cache-Control:must-revalidate:验证方式。must-revalidate意味着在考虑使用一个陈旧的资源时,必须先验证它的状态,已过期的缓存将不被使用。Pragme是HTTP/1.0定义的一个header属性,请求头中包含Pragme的效果与Cache-Control:no-cache相同,但是HTTP响应头中没有明确定义这个属性。
Vary响应 #
- Vary响应头决定了对后续的请求头,如何判断时请求一个新的资源还是使用缓存的文件。
- 当缓存服务器收到了一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能够使用缓存的响应。
二、开放同源限制 #
- 只有来自相同来源的网页才能够获取网站的全部信息。HTTP可以通过修改头部来开放这样的限制。
三、认证 #
- 一些页面能被保护起来,仅让特定的用户进行访问。基本的认证功能可以直接通过HTTP提供。
四、代理和隧道 #
- 通常服务器或客户端都是处于内网,对外网隐藏真实IP。因此HTTP请求就要通过代理越过这个网络屏障。
正向代理 #
- 也可以叫网关,它存储并转发网络服务(如DNS、网页)以减少和控制大家使用的带宽。
- 正向代理代表客户端,可以隐藏客户端的身份。
反向代理 #
-
反向代理代表服务器,可以隐藏服务器的身份。
-
作用:
- 负载均衡:在多个服务器之间分发负载,
- 缓存静态内容:缓存静态内容,为服务器分担压力,
- 压缩:压缩和优化内容以加快传输的速度。
-
代理可以将请求地址设置为自身的ip。
-
Forwarded(标准化版本)首部包含了代理服务器的客户端的信息。- 语法:
Forwarded:by=<identifier>;for=<identifier>;host=<host>;proto=<http|https> - identifier可以是:①ip地址;②语义不明的标识符;③unknown。
by=<identifier>该请求进入代理服务器的接口。for=<identifier>发起请求的客户端以及代理链中的一系列的代理服务器(这意味着要写多个for=)。host=<host>代理接收到的Host首部(Host请求指明了请求将要发送到的服务器主机名和端口号)的信息。proto=<http|https>表示发起请求时采用的何种协议。
- 语法:
-
X-Forwarded-For:在客户端访问服务器的过程中,如果需要经过HTTP代理或者负载均衡服务器,可以使用该参数来获取最初发起请求的客户端的IP地址。- 语法:
X-Forwarded-For:<client>,<proxy1>,<proxy2>...。 - 第一个参数表示客户端的IP地址,如果一个请求经过了多个代理服务器,那么每一个代理服务器的IP都会被依次记录在内。
- 语法:
-
X-Forwarded-Host:用来确定客户端发起请求中使用Host指定的初始域名Host:Host请求头指明了请求将要发送到的服务器的主机名和端口号,所有HTTP/1.1请求报文中必须包含一个Host头字段。
-
X-Forwarded-Proto:用来确定客户端与代理服务器或者负载均衡服务器之间连接所采用的传输协议。
HTTP报文 #
- headers中以x开头的都不是http标准协议
http请求组成 #
- 第一行包括请求方法及请求参数
- 接下来的行每一行都表示一个HTTP首部,为服务器提供关于所需数据的信息
- 一个空行
- 可选数据块,包含更多数据,主要被POST方法使用。
#一个http的动作,如下面的method
#要获取的资源路径,如下面的/chat
#HTTP协议版本号
GET /chat HTTP/1.1
#Headers,为服务器表达其他的信息
#Host指明了要发送到的服务器主机名和端口号,如果没有包含端口号,会自动使用请求服务的默认端口。
Host: xiaoxiang.space
#指明了client的应用类型,操作系统、软件开发商及版本号
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0
#告知服务器客户端可以处理的内容类型,采用mime来表示,;q=表示前面这个类型权重因子,没写就默认是1
Accept: application/json, text/javascript, */*; q=0.01
#客户端声明其能理解的自然语言
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
#会将客户端能够理解的内容编码方式通知给服务端。对应Content-Encoding
Accept-Encoding: gzip, deflate
#指示资源的MIME类型,下面这是post请求的默认格式
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
#加了这个就是ajax异步请求
X-Requested-With: XMLHttpRequest
#用来指明发送给服务器的消息主体的大小
Content-Length: 22
#指示了请求来自哪个站点。仅展示服务器名称,不包含任何路径。
#除了不包含任何路径,该字段与Referer类型。
Origin: https://developer.mozilla.org
#决定当前的事务完成后,是否会关闭网络连接,如果是keep-alive,网络连接就是持久的,使得对同一个服务器的请求可以继续在该连接上完成
Connection: keep-alive
#表示当前页面的来源页面的地址。如果当前页面采用的是非安全协议而来源页面采用的是安全协议时Referer不会被发送。
Referer: http://xiaoxiang.space/index
#是由先前服务器通过Set-Cookie首部投放并存储到客户端。
Cookie: JSESSIONID=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
#对于一些POST这样的方法,报文的body也包含了发送的资源
username=xxx&comment=xxx
HTTP响应组成 #
- 第一行是状态行,包括使用HTTP协议版本,状态码和一个状态描述。
- 接下来的每一行都表示一个HTTP首部,为客户端提供所发送数据的一些信息。
- 一个空行
- 最后一行是数据库,包含了响应的数据
#一个HTTP协议版本号
#一个状态码
#一个状态信息,我这个请求中居然没有???
HTTP/1.1 200
#HTTP headers
#用来向客户端发送cookie,expires表示过期时间
Set-Cookie: xiaoxiang.space=1; Max-Age=3600; Expires=Tue, 23-Mar-2021 11:21:23 GMT
Content-Type: application/json
#指明了将entity安全传递给用户的编码形式,chunked表示数据以一系列分块的形式发送,这种情况下不发送Content-Length。
Transfer-Encoding: chunked
#包含了报文创建的日期和时间。
Date: Tue, 23 Mar 2021 10:21:23 GMT
#需要将Connection首部设为keep-alive这个首部才有意义,可以设置超时时长和最大请求数。
#HTTP/2中Connection和Keep-Alive是被忽略的。
Keep-Alive: timeout=20
Connection: keep-alive
#下面是响应的数据
xxx
参考链接: HTTP Headers - HTTP | MDN
- HTTP消息是服务器和客户端之间交换数据的方式,有两种类型的消息:请求和响应。
HTTP的连接管理 #
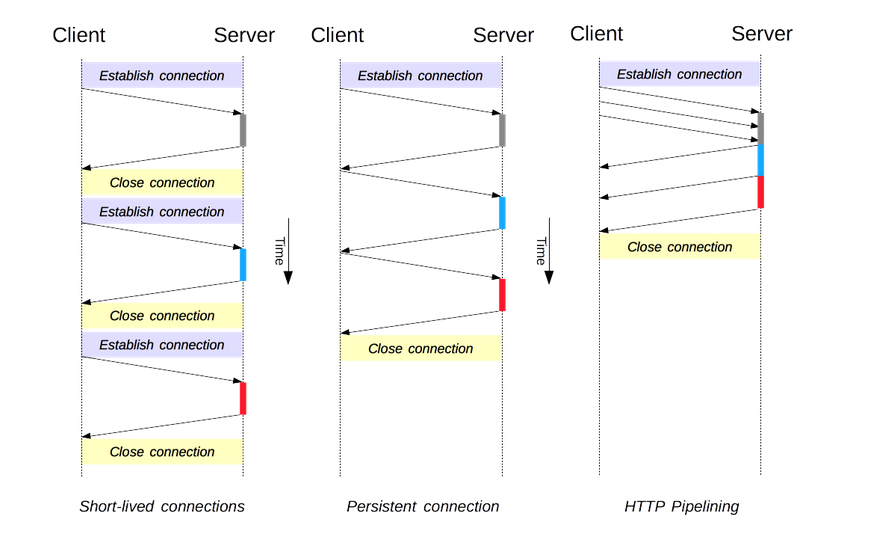
短连接 #
- HTTP/1.0的默认模型,每一次HTTP请求之前都会有一次TCP握手。在HTTP/1.1中,当
Connection被设为Close才会用到这个模型。
长连接 #
- HTTP/1.1中默认就是长连接,一个长连接会保持一段时间,重复用于发送一系列请求,节省了新建TCP连接握手的时间,这个连接会在空闲一段时间后关闭(通过设置
Keep-Alive来指定一个最小的连接保持时间),长连接会消耗服务器资源(毕竟是TCP)。
流水线 #
- 默认情况下HTTP请求是按顺序发出的,下一个请求只有在当前请求收到应答后才会被发出。而流水线是在同一条长链上发出连续的请求。想象很美好,现实很残酷,流水线受制于很多问题。
一个post请求的java程序 #
@Test
public void test3() throws IOException {
URL url = new URL("http://xiaoxiang.space/login/");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//用户可以输出到该URLConnection
connection.setDoOutput(true);
String param = "password=" + URLEncoder.encode("小象", "UTF-8");
//request headers
connection.setRequestMethod("POST");
connection.setRequestProperty("Accept", "text/html");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0");
connection.setRequestProperty("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
//general headers
connection.setRequestProperty("Connection", "close");
//entity headers,必须放在request headers和general headers后面,否则会报错
connection.getOutputStream().write(param.getBytes(StandardCharsets.UTF_8));
//关闭重定向,可以打开试一试
connection.setInstanceFollowRedirects(false);
connection.connect();
System.out.println("\n响应头:");
connection.getHeaderFields().forEach((k, v) -> {
System.out.println(k + ": " + v);
});
//如果有网页的话会输出该网页
InputStream inputStream = connection.getInputStream();
Scanner scanner = new Scanner(inputStream,"utf-8");
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
}