linux命令总结
2021-02-08
linux指令执行过程 #
- linux在下达一个指令时,会按照以下的顺序寻找(所以当直接在bash中输入xxx.sh时是不会执行的):
- 以相对/绝对路径执行指令如/bin/ls,或./ls。
alias lm='ls -al':给命令设定别名;alias:可以查看系统的所有别名;使用unalias lm取消别名。- 由bash内建的指令来执行。
- 通过$PATH这个变量的顺序搜寻到第一个指令来执行。
- 使用
which指令可定位到程序的位置。
linux进程 #
-
进程(process):程序被触发后,执行者的权限与属性、程序及程序所需的数据都会被加载到内存中,操作系统给与这个内存内的单元一个标识符PID。
-
当登入系统后,会取得一个bash,当使用这个bash提供的接口去执行另一个指令时,另外执行的指令也会生成PID,这个新进程就是子进程,而原来的bash环境就是父进程。linux中进程通常由父进程以复制(fork)的方式产生一个一摸一样的子进程,然后被复制出来的子进程再以exec的方式来执行实际要进行的程序,最终就会成为一个子进程。
- 系统先以fork的方式复制一个与父进程相同的暂存进程,这个进程与父进程唯一的差别就是PID不同,此外这个暂存进程还会多一个PPID(parient pid)的参数。
- 暂存进程开始以exec的方式加载实际要执行的程序。
-
常驻内存中的进程通常提供一些功能以服务用户,因此这些常驻程序就会被称为:服务(daemon)。
lspci 获取本机PCI相关信息 #
lspci -tv显示PCI树和树上设备的名称。lspci -vvvs bus:device.function显示此设备的配置空间,-vvv也可以是-vv,信息会少一点。例:lspci -vvvs 2c:00.0。lspci -xxxxs bdf以十六进制显示PCI设备的配置空间。lspci -vvv获取所有设备的配置空间。
setpci 设置PCIe配置空间 #
setpci -s b:d.f reg.[B|W|L]=value写PCIe配置空间reg寄存器的值,其中B表示一个字节,W表示两个字节,L表示四个字节。例:setpci -s 60:03.1 0x60.b=0x57
dmidecode 获取SMBIOS信息 #
dmidecode -t9获取主机槽位信息。
ext4文件系统调试 #
- 获取文件的inode
ls -ila。 - 读取文件的inode信息
stat /etc/passwd(需要指定全路径)。 - 获取inode所在的block位置
debugfs /dev/sda1 -R "imap <6029951>" | tee。 - 将十六进制转为十进制并显示
echo $((0x4002))。 - 获取文件系统类型
df -Th。-T表示打印文件系统Type。通过df -i还能看到文件系统当前的inode总数和剩余inode数量。 - 根据inode号获取inode信息和data block的位置
debugfs /dev/sda1 -R "stat <6029951>" | tee,使用tee看起来更直观。 - 查看super block和group descriptors的信息
dump2fs /dev/sda1。 - 读取磁盘指定block位置的数据
dd if=/dev/sda1 bs=4096 count=1 skip=6327982,其中if表示输入文件,bs表示块大小,count表示几个快,skip表示跳过多少块。可以使用xxd来显示十六进制dd if=/dev/sda1 bs=4096 count=1 skip=6327982 | xxd。 - 文件被删除后,在目录下是看不到该文件的,但是该文件的inode信息其实还存放在目录中,可以通过如下命令拿到文件的inode号
debugfs /dev/sdd3 -R "ls -d /dir1"(注意,此路径不是挂载的全路径,而是直接从文件系统的根路径开始)。 - 删除文件只是将文件inode中的block数组给置零了,文件内容其实没有删除。
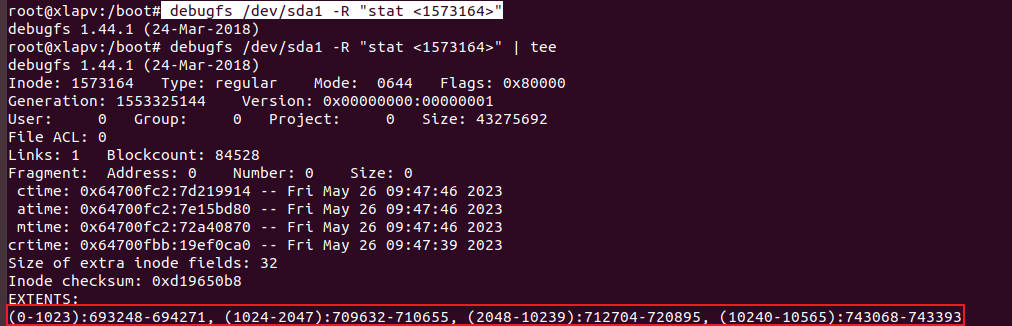
- 例(查看inode的extent信息):
- 使用
ls -li获取inode number。
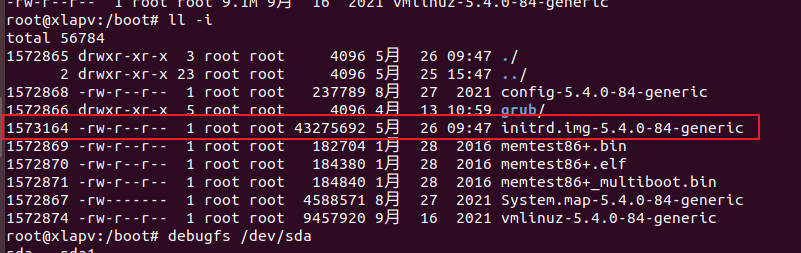
- 查看此inode的信息。
debugfs /dev/sda1 -R "stat <1573164>"
- 或取此inode所在的块。
debugfs /dev/sda1 -R "imap <1573164>" | tee

- 根据块号和偏移量找到相应的inode的数据。
dd if=/dev/sda1 count=1 bs=4096 skip=6291506 |xxd

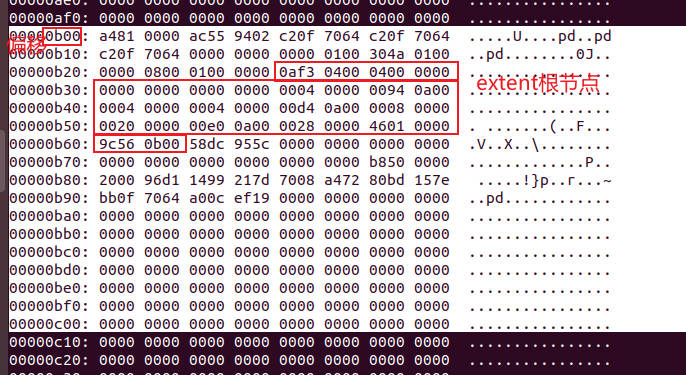
- 解析后的结果如下:
- 使用
//0af3 0400 0400 0000 0000 0000
ext4_extent_header
{
eh_magic = 0xF30A //magic number 2byte
eh_entries = 4 //header之后的entry数量 2byte
eh_max = 4 //header之后最大的entry数量 2byte
eh_depth = 0 //树的深度 2byte
eh_generation = 0
}
//第一个extent 0000 0000 0004 0000 0094 0a00
struct ext4_extent
{
ee_block = 0 //当前是第几个块(这里的块和文件系统的块不同) 4byte
ee_len = 1024 //多少个块 2byte
ee_start_hi = 0 //块号高16位 2byte
ee_start_lo = 693248 //块号低16位 4byte
}
//第二个extent 0004 0000 0004 0000 00d4 0a00
struct ext4_extent
{
ee_block = 1024 //当前是第几个块(这里的块和文件系统的块不同) 4byte
ee_len = 1024 //多少个块 2byte
ee_start_hi = 0 //块号高16位 2byte
ee_start_lo = 709632 //块号低16位 4byte
}
//第三个extent 0008 0000 0020 0000 00e0 0a00
struct ext4_extent
{
ee_block = 2048 //当前是第几个块(这里的块和文件系统的块不同) 4byte
ee_len = 8192 //多少个块 2byte
ee_start_hi = 0 //块号高16位 2byte
ee_start_lo = 712704 //块号低16位 4byte
}
vim 文本编辑工具 #
通过配置~/.vimrc(不建议修改/etc/vimrc)可以设定一些vim的属性,在vim的命令模式输入:set all可以查到
ctrl+f向下移动一页ctrl+b向上移动一页0或者home移动到这一列的最前面$或end移到这一列最后一页G(注意是大写)移到文件的最后一列gg移到文件的第一行n+enter光标向下移动n行/word搜索为名称为word的字符串:1,2s/word1/word2/g[第一行,第二行]中所有的word1被替换成word2:1,$s/word1/word2/g第一行到最后一行所有word1被替换为word2:1,$s/word1/word2/gc第一行到最后一行所有word1被替换为word2,且在取代前会提示字符给用户确认dd删除当前一整行,ndd删除光标所在的向下n行yy复制一整行,4yy复制4行。p将复制的数据在光标的下一行粘贴,P在光标的上一行粘贴u复原前一个动作ctr+r重复上一个动作:w [filename]将文件另存为:set nu/nonu开启/关闭行号:set ic忽视大小写
nmcli 网络配置工具 #
-
目前主流网卡为使用以太网络协议开发出来的以太网卡(Ethernet),所以linux称呼这种网络接口为ethN(N为数字)。新的centos7对网卡的编号有另一套规则,网卡待会现在与网卡的来源有关:eno1(BIOS内建的网卡),ens1(BIOS内建的PCI-E网卡),enp2s0(PCI-E)界面的独立网卡。
-
nmcli可用来设置ip、dns等配置,与直接修改/etc/sysconfig/network-scripts/ifcfg-xxx(centos7)、/etc/NetworkManager/system-connections/ethernet-xxx(ubuntu18)等效。
-
一个网卡设备可以有多个配置,但是只能有一个为激活状态,多个配置可以在不同的网络环境中切换。比如小明在公司用静态IP的方式连接到网络,在家用DHCP的方式连接网络,可以创建两个connections,一个叫static-conn,另一个叫dhcp-conn,当需要使用DHCP的方式时,执行
nmcli con up dhcp-conn激活配置,当使用静态IP的方式时,执行nmcli con static-conn激活配置。
nmcli connection {show | up |down| modify | add | edit |clone | delete |monitor | reload | load | import | export } ARGUMENTS...
#为网卡enp0s8创建一个配置
nmcli connection add ifname enp0s8 type ethernet ipv4.method auto
#在一个交互式的窗口中为ethernet-enp0s8编写配置
nmcli connection edit ethernet-enp0s8
#修改ethernet-enp0s8的网络参数
nmcli connection modify enp0s8 \
connection.autoconnect yes \ #是否开机就启动这个配置
ipv4.method manual \ #自动(DHCP)还是手动设定网络参数
ipv4.addresses 192.168.x.x/24 \ #设定地址
ipv4.gateway 192.168.x.x \ #设定网关
ipv4.dns 192.168.x.x #设定DNS
ipv4.never-default yes #设定不为默认路由
#移除某个配置,只需要将该配置的值置为空
nmcli con modify ethernet-enp0s8 ipv4.dns ""
#为ethernet-enp0s8添加dns的配置(因为dns和ip能有多个配置,所以可以用+和-,不能有多个配置的不能用)
nmcli con modify ethernet-enp0s8 +ipv4.dns 8.8.8.8
#为ethernet-enp0s8删除ip的配置
nmcli con modify ethernet-enp0s8 -ipv4.addresses "192.168.100.25/24"
#修改配置名称
nmcli connection modify ethernet-enp0s8 con-name
#列出所有的配置。
nmcli connection show
#仅列出激活状态的配置。
nmcli connection show --active
#列出ethernet-enp0s8的配置。
nmcli connection show ethernet-enp0s8
#激活enp0s8设备的配置。
nmcli connection up ifname enp0s8
#激活名称为ethernet-enp0s8的配置。
nmcli connection up ethernet-enp0s8
#删除ethernet-enp0s8的配置
nmcli connection delete ethernet-enp0s8
#导入一个openvpn的配置给networkmanager
nmcli con import type openvpn file ~/Downloads/frootvpn.ovpn
#增加一个ip地址(多ip地址)
nmcli c modify mark +ipv4.addresses 10.2.0.31/24
#去掉一个ip地址
nmcli c modify mark +ipv4.addresses 10.2.0.31/24
/etc/network/interfaces网络配置 #
- 修改/etc/network/interfaces配置文件
#指定 enp0s3 接口在启动时自动激活。
auto enp0s3
#指定 enp0s3 接口的配置方式为静态 IP 地址。
iface enp0s3 inet static
address 192.168.1.110
netmask 255.255.255.0
gateway 192.168.1.1
- 重启使配置生效
/etc/sysconfig/network-scripts/ifcfg-xxx配置介绍 #
#最小配置
DEVICE=eth1 #网卡号,必须与文件名对应
ONBOOT=yes #是否默认启动,要联网必须要配置
BOOTPROTO=none #是否使用dhcp,是的话BOOTPROTO=dhcp
HWADDR=08:00:27:35:2F:f2 #mac地址
IPADDR=172.27.32.6 #ip地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=172.27.32.1 #网关
firewall-cmd centos7下的防火墙工具 #
#查看防火墙的状态
systemctl status firewalld
#关闭防火墙并禁止开机自启
systemctl stop firewalld; systemctl disable firewalld
#启用防火墙并允许开机自启
systemctl start firewalld; systemctl enable firewalld
-
防火墙的服务名为firewalld,centos7使用firewall-cmd来管理防火墙。
-
firewalld预先准备了几套防火墙策略集合(zone)。常见的zone:1. trusted允许所有的数据包;2. home;3. internal;4. work;5. public;6. external;7.dmz;8. block;9.drop。
-
常见命令:
- –get-default-zone查询默认的zone;- -set-default-zone设置默认的zone,–get-zones显示可用的zone;
- –list-all显示当前区域的网卡配置参数、资源、端口及服务等信息; –list-all-zones显示所有区域的网卡配置参数、资源、端口及服务等信息;
- –add-service=服务名、–remove-service=服务名;
- –add-port=端口号/协议、–remove-port=端口号/协议;–list-ports列出已开放的端口。
- –add-forward-port=port=源端口号:proto=协议:toport=目标端口号:toaddr:目标ip地址。
- –panic-on/–panic-off启动/关闭应急状态,阻断一切网络连接。
-
firewalld设置只在下次重启前有效,如果需要永久生效,需要加上–permanent模式,并执行firewall-cmd –reload。
#永久放开3306端口,并立刻生效
firewall-cmd --add-port 3306/tcp --permanent
firewall-cmd --reload
#永久拒绝192.168.10.0/24网段的所有用户访问本机的ssh服务。
firewall-cmd --permanent --zone=public --add-rich-rule="rule family="ipv4" source address="192.168.10.0/24" service name="ssh" reject"
nmap #
nmap [扫描类型] [扫描参数] [主机地址]
扫描类型:
-sS:扫描TCP,通过SYNACK报文判断
-sP:以ping的方式扫描
-sT:扫描TCP,通过建立tcp连接
-sU:扫描UDP
扫描参数:
-p 扫描端口,如80,80-1023等
主机地址:
如192.128.0.0/24,192.168.1.100,192.168.1.1-50,60-100
nmap -sS 10.2.4.2
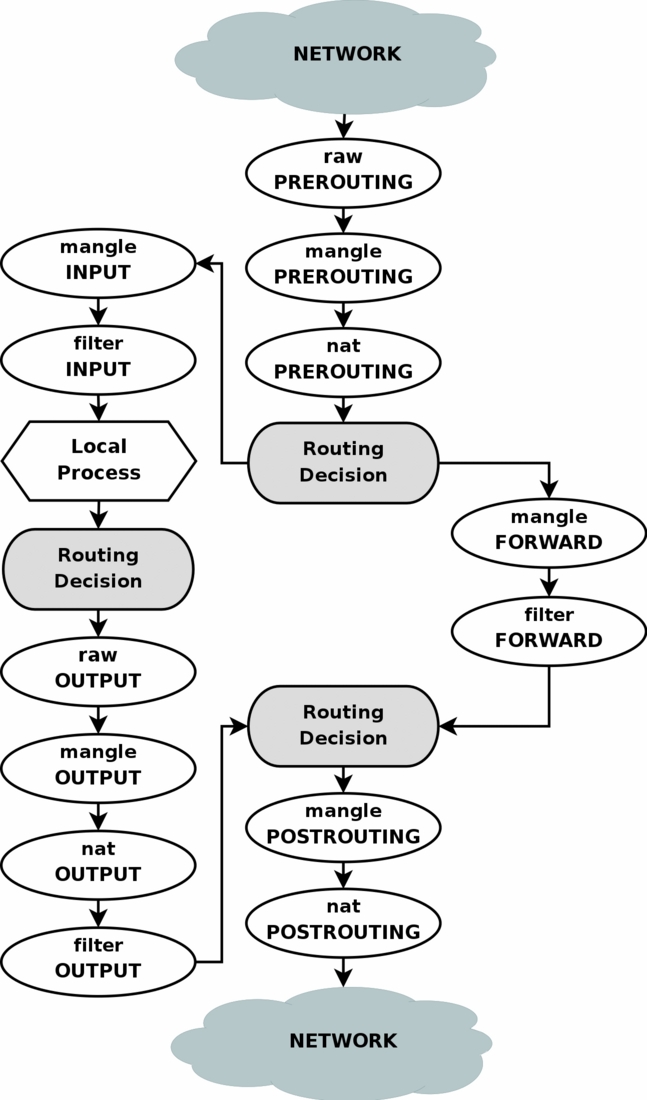
iptables #
-
REDIRECT用于将数据包转发到本机,数据包目的地址将映射到127.0.0.1地址,只能用于nat表的PREROUTING和OUTPUT。
-
iptables有4张表,每个表和其中的链用途如下:
- filter(过滤器):主要跟进入Linux本机的数据包有关
- INPUT:进入Linux的数据包
- OUTPUT:Linux发出去的数据包
- FORWARD:和Linux本机无关,他可以转发封包到后面的计算机
- nat(地址转换):主要是进行IP或端口的转换:
- PREROUTING:在进行路由判断之前要进行的规则(DNAT/REDIRECT)
- POSTROUTING:在进行路由判断之后要进行的规则(SNAT/MASQUERADE)
- OUTPUT:与发出去的数据包有关
- mangle(破坏者)
- raw
- filter(过滤器):主要跟进入Linux本机的数据包有关
-
查看防火墙规则
iptables [-t tables] [-L] [-nv]
-t 后面跟表名,默认为filter
-L 列出目前table的规则
-n 不获取HOSTNAME,速度快
-v 显示更多信息
--line-numbers 显示行号
结果介绍:
Chain那一行的括号里的policy就是预设的策略。
---
target:表示进行的动作,ACCEPT是放行,REJECT是拒绝,DROP是丢弃。
prot:表示协议,如tcp、udp、icmp。
in:表示输入网口
out:表述输出网口
source:表示此规则是针对哪个来源做处理
destination:表示此规则是针对哪个目标进行限制
说明栏:
- 设定预设规则
iptables [-t nat] -P [INPUT, OUTPUT, FORWARD] [ACCEPT, DROP]
相关命令 #
- 删除进入的数据包
#拒绝来自10.2.4.2 tcp20000端口的数据包,使用REJECT会返回一个port-unreachable的ICMP
iptables -A INPUT -s 10.2.4.2 -p tcp --dport 20000 -j REJECT
#拒绝来自10.2.4.5的数据,将此规则插入到链第二个节点
iptables -t filter -I INPUT 2 -s 10.2.4.5 -j REJECT
- 数据包复制和重定向
#(10.2.4.56主机)将5140 udp端口的数据复制一份到10.2.4.31上
iptables -t mangle -A PREROUTING -p udp --dport 5140 -j TEE --gateway 10.2.4.31
#(10.2.4.31主机)将目标IP地址为10.2.4.56、udp端口为5140的数据转发到本地的5141端口
iptables -t nat -A PREROUTING -d 10.2.4.56 -p udp --dport 5140 -j REDIRECT --to-ports 5141
- 规则删除
#删除nat表PREROUTING链的第二条规则
iptables -t nat -D PREROUTING 2
systemctl 管理unit #
- 一般linux上的服务会在服务名后面加上一个d,这个d就表示daemon。
- systemd将daemon执行脚本称为的一个unit。一般情况下安装的应用的unit都会放到
/usr/lib/systemd/system/下;而在/etc/systemd/system/目录下会存放unit的一些配置。 - unit有多种类型,包括 ①service:服务类型;②socket;③target:执行环境类型,是一群unit的集合;④mount、automount:文件系统挂载相关的服务;⑤path:侦测特定的文件或目录类型;⑥timer:循环执行的服务。常用的即使service和target,比如mysqld.service(mysql服务),firewalld.service(防火墙)。
- 通过systemctl可以管理unit,格式如下:
systemctl [command] [unit],其中command如下:- start:启动。例
systemctl start mysqld.service。 - stop:停止。
- enable:开机启动。例
systemctl enable mysqld.service。 - disable:禁止开机启动。
- status:unit的状态。
- is-active:是否运行。
- start:启动。例
- 执行
systemctl status xxx,会显示该unit的状态。结果的第二行表示该服务是否会开机启动,结果的第三行表示该服务的当前状态。 - 一个daemon的预设状态有多个,包括:
- enabled:这个daemon会在开机被执行。
- disabled:这个daemon在开机不会被执行。
- static:这个daemon不可以自己启动(即不能使用
systemctl enable xxx来设置开机自启),但可以被其他的服务来唤醒。 - mask:注销状态,这个daemon无法被启动,可以通过
systemctl unmask xxx改会原来的状态。
systemctl [list-units]列出目前启动的unit;systemctl list-units --all列出所有的unit。systemctl list-unit-files列出所有已安装的unit。
unit文件说明 #
Unit #
- Description: 当前unit的描述
- Documentation:文档地址,可接受 “
http://”,"https://","file:","info:", “man:” 五种URI类型。 - Requires:表示本unit和其他unit之间有强依赖关系。
- Wants:是
Requires=的弱化版。当此单元被启动时,所有这里列出的其他单元只是尽可能被启动。但是,即使某些单元不存在或者未能启动成功,也不会影响此单元的启动。推荐使用此选项来设置单元之间的依赖关系。 - Before、After:强制指定unit的启动顺序,不涉及依赖关系。
- OnFailure:接受一个空格分隔的单元列表,当单元启动失败时,将会启动列表中的单元。
- 相关链接: systemd.unit 中文手册
service类型的unit特有的的Service #
-
Type
- simple:如果设为
simple,那么ExecStart=进程就是该服务的主进程,systemd 会认为在创建了该服务的主服务进程之后,该服务就已经启动完成。如果execStart指定的可执行文件不存在或User=的用户不存在,systemctl start也仍然会执行成功。除了simple之外的类型都需要等待服务完成初始化,所以可能减慢系统启动速度。 - exec:和simple类似,但该服务只有在主服务的进程执行完成后,systemd才会认为该服务启动完成。
simple表示当fork()函数返回时,即算是启动完成,而exec则表示仅在fork()与execve()函数都执行成功时,才算是启动完成。对于exec来说,如果不能成功调用主服务进程(如User不存在、后可执行文件不存在),则systemctl start会执行失败。 - forking:ExecStart=进程将会在启动过程中使用
fork()系统调用。也就是当所有通信渠道都已建好、启动亦已成功之后,父进程将会退出,而子进程将作为主服务进程继续运行。在这种情况下,systemd 会认为在父进程退出之后,该服务就已经启动完成。如果使用了此种类型,那么建议同时设置PIDFile=选项,以帮助 systemd 准确可靠的定位该服务的主进程。systemd 将会在父进程退出之后立即开始启动后继单元。 - oneshot:只有当该服务的主服务进程退出后,systemd才会认为该服务启动完成。通常需要设置 RemainAfterExit=yes ,使、systemd 在服务进程退出之后仍然认为服务处于激活状态。
notify与exec类似,不同之处在于,该服务将会在启动完成之后通过 sd_notify(3)之类的接口发送一个通知消息。idle与simple类似,不同之处在于,服务进程将会被延迟到所有活动任务都完成之后再执行。这样可以避免控制台上的状态信息与shell脚本的输出混杂在一起。注意:(1)仅可用于改善控制台输出,切勿将其用于不同单元之间的排序工具;(2)延迟最多不超过5秒,超时后将无条件的启动服务进程。
- simple:如果设为
-
ExecStart:启动服务时需要执行的命令+参数。
-
ExecReload:用于设置该服务被要求重新载入配置时需要执行的命令行。有一个特殊的环境变量$MAINPID用于表示主进程的PID,可以这样使用
/bin/kill -HUP $MAINPID。 -
ExecStop:用于设置服务被要求停止时所执行的命令行。
-
Restart:当服务经常正常退出、异常退出、被杀死、超时的时候,是否重新穷该服务。可以为on、on-success、on-failure、on-abnormal、on-watchdog、on-abort、always之一。默认是no。always表示服务会被无条件的重启,on-success表示仅在服务进程正常退出时重启,正常退出是指:退出代码为0或进程收到 SIGHUP, SIGINT, SIGTERM, SIGPIPE 信号之一, 并且 退出码符合 SuccessExitStatus= 的设置。on-failure 表示 仅在服务进程异常退出时重启, 所谓"异常退出" 是指: 退出码不为"0", 或者 进程被强制杀死(包括 “core dump"以及收到 SIGHUP, SIGINT, SIGTERM, SIGPIPE 之外的其他信号)。
-
退出原因(↓) | Restart= (→) noalwayson-successon-failureon-abnormalon-aborton-watchdog正常退出 X X 退出码不为"0” X X 进程被强制杀死 X X X X systemd 操作超时 X X X 看门狗超时 X X X X -
RestartSrc:设置在(Restart)前暂停多长时间,默认值为100ms,如果未指定时间单位,默认单位是秒。
-
相关链接: systemd.service 中文手册
service #
- KillMode:设置单元停止时,杀死进程的方法:control-group、process、mixed、none。默认值是control-group。
install #
- WantedBy:表示在使用systemctl enable启用此单元时,将会在每个列表单元的.wants下创建一个指向该单元的软链接,相当于为每个列表中的单元文件添加了Wants=此单元选项,这样当单元启动时,该单元就会被启动。注:
multi-user.target通常是包含在graphical.target中。
[root@localhost ~]# cat /usr/lib/systemd/system/nginx.service
[Unit]
Description=nginx
[Service]
Type=forking
PIDFile=/opt/nginx/logs/nginx.pid
ExecStart=/opt/nginx/sbin/nginx
ExecReload=/opt/nginx/sbin/nginx -s reload
Restart=on-failure
ExecStop=/opt/nginx/sbin/nginx -s quit
[Install]
WantedBy=multi-user.target
- systemd取消了以前的runlevel概念,转而使用不同的target操作环境。常见的操作环境为multi-user.target(命令行界面)和graphical.target(图形界面)。不重新启动而转不同的操作环境使用
systemctl isolate unit.target,设定预设的环境使用systemctl set-default multi-user.target。
RPM 软件管理机制 #
-
RPM全称:RedHat Package Manager
-
RPM是通过预先编译打包成RPM文件格式后,再加以安装的一种方式。RPM在打包软件的同时会加入一些其他的信息,包括软件版本、作者、依赖的其他软件等。RPM会在linux系统上建立一个RPM软件数据库,当要安装某个软件时,RPM会去在数据库里检测是否已经存在相关软件,如果不存在就不能安装。
-
当软件安装完毕后,该软件相关的信息就会被写入到
/var/lib/rpm目录下的数据库文件中了。未来任何软件升级的需求,版本之间的比较都是来自于这个数据库。 -
rpm -ivh package_name安装软件- -i install;-v查看安装信息界面;-h显示安装进度
- –force:强制安装,–test:测试一下该软件是否可以被安装到linux中
- –prefix 新路径:将软件安装到其他路径
-
rpm -Uvh/-Fvh file-1.0-1.e17.x86_64.rpm更新软件- -U:update后面的软件即使没有安装过,系统会直接安装,如果安装过旧版,系统会更新到新版。
- -F:freshen后面的软件如果没有安装就不安装,如果安装过旧版就更行到新版。
-
rpm -qa查询本机所有已安装软件rpm -q package_name查询后面的软件是否被安装rpm -qi package_name列出该软件的详细信息rpm -ql package_name列出该软件所有文件与目录rpm -qR package_name列出该软件依赖那些软件rpm -qpR file-1.0-1.e17.x86_64.rpm查询某个rpm文件依赖了哪些文件,-p表示指定的是一个rpm文件。- tips:在查询本机上已安装的软件时,只用加上软件的名称即可,版本号啥的都不需要。
yum 包管理工具 #
当客户端有软件安装需求时,客户端会主动下载yum服务器中该软件的依赖清单,将该清单与本机的RPM数据库进行比较,就能安装未安装的依赖了。
yum提供了查找、安装、删除软件包的命令。
yum [options] [command] [package ...]
- options:可选,-y表示安装过程全部为yes,-q白哦是不显示安装过程,-h表示帮助,–installroot=路径:将软件安装到指定路径中。
- command:要进行的操作,如search、list、info。
- package:包名。
常用命令 #
yum check-update列出所有可更新的软件。yum update更新所有软件yum install package_name安装指定的软件yum update package_name更新指定的软件yum list列出所有的可安装的软件yum list packa*寻找以packa开头的软件
yum remove package_name删除软件yum search keyword_name查找软件包命令- yum会先下载软件库的清单到本机的
var/cache/yum中,清除缓存命令如下yum clean packages/headers/all清楚缓存目录下的软件包/headers/所有软件库的数据。
netstat 显示网络状态 #
netstat -tulnp用来获取目前主机已启动的服务- -t/-u显示tcp/udp传输协议的连接情况
- -l显示监听状态的的服务
-a显示所有连线中的socket-n:显示数字而不是别名- -p显示socket的pid/程序名
tcpdump 抓包命令 #
-i interface监听指定的interface,如果未指定此参数,tcpdump会搜索系统interface上数字最小的interface(如eth0)监控。可以用-i any来监控所有的interface(此参数不会在promiscuous mode下工作)。-X显示原始16进制数据内容和ascii编码后的内容。-D列出系统上可用的网络接口。-A以ASCII的方式打印出每个包(不包括链路层头部)。-nn显示原始的ip地址和端口。-v产生详细的输出. 比如包的TTL,id标识,数据包长度,以及IP包的一些选项。-w将抓到的数据包写入到文件中。- tcpdump
- 例子
#以ASCII的形式显示在本机所有网卡、端口5140上监听的数据
tcpdump -A -i any -n port 5140
#监听端口不是5140
tcpdump -A -i any -n ! port 5140
#抓来源是10.0.1.81,目的端口是5140的数据
tcpdump -i any -nnA src host 10.0.1.81 and dst port 5140
#同时指定两个端口
tcpdump -i any -nnA port 8848 or port 5140
tcpdump -i any -nnA port 8848 or 5140
#指定端口范围
tcpdump -i any -nnA portrange 514-5140
#将抓到的数据保存到文件中
tcpdump icmp -w icmp.pcap
tcpdump icmp -r icmp.pcap
curl 强大的网络工具 #
-
(client url)通过指定的url上传或者下载数据。
-
curl xiaoxiang.space查看网页源码。 -
curl -o [文件名] xiaoxiang.space保存文件。 -
使用
-L参数,当有重定向时,会跳转到新的网址。 -
-i显示http response的头信息,同时也会显示网页代码。 -
-I/--head只显示http response。 -
-v显示一次http通信的整个过程。 -
发送get请求和参数,直接把数据附加到网址后面就行。
-
curl -X POST --data-urlencode "data=xxx" example.com/xxx发送post请求。-X参数可以支持几个动词。 -
--User-Agent、--cookie等,--header增加一个头信息。 -
--user name:passwordhttp认证。 -
-k跳过ssl检测。 -
--limit-rate限制HTTP请求和回应的带宽。
ps 获取当前时刻系统进程状态 #
ps aux查询所有系统运行的进程- %CPU:使用的cpu资源百分比;%mem:使用的内存资源百分比;vsz:使用的虚拟内存Kb;rss:占用的固定内存Kb;tty:该进程是在哪个终端机上运行,如果于与终端机无关则显示?;stat:进程目前状态(R运行;S睡眠但可被唤醒;D不可被唤醒;T停止状态;Z僵尸状态);time:实际使用cpu的时间。
--sort +rss按照rss以递增[+]或者递减[-]的顺序排序 。
#按照cpu占用从大到小排序 并一页一页的显示
ps aux --sort -%cpu | more
- 使用
ps -lf显示当前的bash的进程。- -l时较详细的输出当前bash的信息,-f是更完整的输出。🤣
- 输出中的S代表该进程的状态,主要的状态有:R running;S sleep;D 不可唤醒的睡眠状态,而可能是在等待I/O;T 停止状态;Z zombie僵尸状态。
- PRI/NI priority/nice 代表此进程被cpu所执行的优先级。PRI值越低代表优先级越高。优先级是由内核动态调整的,用户无法干涉,如果需要调整进程的优先执行次序时,可以通过修改Nice的值。一般来说有PRI(new)=PRI(old)+nice,但是最终的PRI也是有系统分析后决定的,nice的值有正有负,当nice为负数时,该进程就会降低pri值,所以会被较为优先的处理。nice的值的范围是
-10~19。一般使用者仅可以调整自己进程的nice值,范围为0~19,且只能将nice调高。使用nice和renice调整。- nice:新执行的指令给予新的nice值
nice [-n 数字] command。 - renice:已存在进程的nice重新调整
renice [-number] PID。
- nice:新执行的指令给予新的nice值
- ADDR/SZ/WCHAN addr标识该进程在cpu的哪个部分,如果是running的进程,一般就会显示-,sz代表该进程用掉了多少的内存。wchaz代表进程目前是否在运行中。
- TIME代表使用掉的cpu的时间。
ps axjf可以列出来类似进程树的进程显示。pstree [-Apu]-p显示每个进程的pid,-u显示每个进程的所属账号。-A各个进程之间以ascii字符来连接。- 相关文档 The ps Command
top 动态显示进程状态 #
-
top [-d n]每隔n秒(默认为5)更新一次- 第一行显示的是:当前时间、开机到现今经过的时间、登入系统的人数、系统在1、5、15分钟的平均工作负载
- 第二行显示进程总量、进程状态;第三行显示cpu整体负载;第四行和第五行显示物理内存和虚拟内存的使用情况。
- 第三行(%Cpus…)显示的是CPU的整体负载,wa表示I/O wait
- PR:priority,指进程的优先级、NI:Nice,于PR有关;TIME+表示CPU使用时间的累加
- 执行过程中按下M表示以内存的使用来排序,N表示已PID来排序,P表示以CPU来排序,T表示以TIME+来排序,按下q可以离开top
-p PID观察指定PID- 在top执行过程中可以按下**
P使得以CPU的使用资源排序,按下M以内存的使用资源排序,按下N**以PID来排序。按下c显示完整的路径和名称。
kill 向进程发送signal #
kill -9 PID立刻强制删除一个工作kill [-15] PID以正常的方式结束一个工作- 例:当使用vim时,会产生一个.filename.swp文件,使用-15时,vim会以正常的步骤结束vi的工作,所以.filename.swp会被主动的移除,但如果使用-9,由于vim工作被强制移除了,所以.filename.swp就会继续存在文件系统中。
- 当想要进程执行某些动作时,可以给该进程一个工作号码,可以使用
kill -l或者man 7 signal查到,主要的信号与名称对应关系。
| signal | 内容 |
|---|---|
| 1 SIGHUP | 启动被终止的进程,可以让该PID重新读取自己的配置文件,类似于重新启动 |
| 2 SIGINT | 相当于用键盘输入一个ctrl-c来中断一个进程的执行 |
| 9 SIGKILL | 强制中断一个进程的进行 |
| 15 SIGTERM | 以正常的结束进程来终止该进程 |
| 19 SIGSTOP | 相当于使用键盘ctrl-z来暂停一个进程的执行。 |
- kill可以帮我们将signal传递给某个%jobnumber(参考下面的job和fg命令)或者某个PID。
nohup和& 后台执行 #
- nohup会将标准输入重定向到/dev/null,将标准输出重定向到nohup.out(一般情况)或$HOME/nohup.out文件,将标准错误输出重定向到标准输出。
nohup COMMAND > FILE保存输出内容到文件。nohup COMMAND &后台执行命令。- 使用
&可以将任务丢到后台执行,但标准输出和标准错误输出仍然会被输出到屏幕上。 &将进程放到了背景执行,但是当退出bash后,进程就会被终止掉,如果需要退出bash后进程仍然能继续执行,可以使用nohup。nohup能在退出bash后还能继续执行工作。- 例:
nohup java -jar xxx.jar </dev/null 2>&1 &将java命令放到后台执行,标准输出和标准错误输出都重定向到/dev/null
sed 正则工具 #
sed [-nefr] [n1[,n2]] function。- -i 直接修改读取的文件;-n只有经过sed处理的行会被输出(配合q使用)。
- n1,n2表示选择进行操作的行数。
- function有:a 新增到的当前下几行;c 取代;d 删除;i 插入到当前的上一行;p 打印;s 取代,如1,20s/old/new/g。
#将显示到屏幕的内容删除第2-5行
nl /etc/passwd | sed '2,5d'
#删除第三行到最后一行
nl /etc/passwd | sed '3,$d'
#在第二行后面加上drink tea(就是加在了第三行)
nl /etc/passwd | sed '2a drink tea'
#在第二行后面加上了两行,每一行之间都要以反斜杠\来进行新行的增加
nl /etc/passwd | sed '2a drink tea \
drink beer'
#取代2-5行
nl /etc/passed | sed '2,5c No 2-5 number'
#仅列出/etc/passwd文件的第5-7行
nl /etc/passwd | sed -n '5,7p'
#删除5-7行
nl /etc/passwd | sed '5,7 d'
#去掉开始的空格,删除以1和2开始的行
nl /etc/passwd |sed 's/^ *//g' | sed '/^[1-2]/d'
#去掉有#注释的行和空白行
cat server.properties | sed '/^#/d' | sed '/^\s*$/d'
#将行末尾的.改为!
sed -i 's/\.$/\!/g' regular_express.txt
#文件的最后一行增加一行文字
sed -i '$a # This is a test' regular_express.txt
#删除文件中\r
sed -i 's/\r//g' file.txt
- 取代命令
sed 's/要被取代的字符串/新的字符串/g'
awk 数据处理工具 #
awk '条件类型1{动作1}' filename,awk只能用单引号。- awk默认以空格或者[Tab]按键隔开,隔开的每一行的每个字段都是有变量名称的,那就是$1、$2…。$0表示一整行。
- NF表示每一行的字段总数;NR表示目前是第几行;FS表示目前的分割字符,默认是空格
- 参数-F可以指定分隔符,如
awk -F : '{print $(NF -1)}'
#输出账号和ip,有些数据格式不对
last -n 5 | awk '{print $1 "\t" $3}'
last -n 5| awk '{print $1 "\t lines: " NR "\t columns: " NF}'
#将分割字符设为冒号:,查询第三栏小于10,并只输出账号和第三栏
cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
#杀掉所有的java程序
jps |grep -vi jps | awk '{print $1}' | xargs -n 1 -I {} kill {}
job和fg 前台执行 #
- 可以使用
ctrl+z将任务丢到背景,状态是暂停。 - 使用
jobs -l可以观察当前背景中的任务。其中+代表最近被放到背景,-代表最近倒数第二个被放到背景。 - 使用fg可以将背景工作拿到前台来执行。命令:
fg &jobnumber。 - 删除背景中的工作。命令:
kill [-15 |-9] %jobnumber。
at与cron #
at 只执行一次的任务 #
- 要使用at,需要先启动atd。我们使用at这个指令来产生要运行的工作,并将这个工作以文本文件的方式写入到/var/spool/at/目录内,该工作就能等待atd这个服务的取用与执行。
- at会先寻找/etc/at.allow这个文件,写在这个文件中的使用者可以使用at,不在这个文件中的用户不能使用at,即使用户没有写在at.deny中。如果不在这个文件中,at会寻找/etc/at.deny这个文件,写在这个文件中的使用者不能用at,不在这个文件中的使用者可以使用(也就是说两个文件存在一个就可以)。如果两个文件都不存在,就只有root可以执行at。
- at会将所有的标准输出和标准错误输出传送到执行者的mailbox中,解决方法是
echo "hello world" > /dev/tty1。
at [-ldv] TIME
-l 相当于atq,列出当前系统上面所有当前用户的未执行的at排程。
-d 相当于atrm,取消一个在at排程中的工作
-c 列出后面接的第几项项工作的实际指令内容at -c 2
TIME: HH:MM [YYYY--MM-DD] 18:02 2021-10-29
HH:MM [Month] [Date] 18:02 October 29
HH:MM[am|pm] + number [minutes|hours|days|weeks]
#再过5分钟后执行,ctrl+d退出
at now + 5 minutes
#查询还没执行的任务
atq
#删除3这个任务
atrm 3
cron 定时任务 #
- 与at类似,cron也有两个限制文件,/etc/cron.allow和/etc/cron.deny,/etc/cron.allow比deny要优先,两个文件只选择一个来限制,所以保留一个即可。系统默认保留/etc/cron.deny。
- 当用户使用crontab指令来建立工作排程后,该项工作就会被记录到/var/spool/cron里面去,而且以账号来判别。cron执行的 每一项工作都会被记录到/var/log/cron这个文件中。
- 下达指令最好使用绝对路径;cron会每分钟去读取一次/etc/crontab与/var/spool/cron里面的数据,所以编辑完文件后,cron会按照设定自动执行。
- 放到
/etc/cron.hourly目录内的所有执行文件(必须是shell脚本)会在每小时的一分钟开始后的5分钟内随机选择一个时间点来执行(详细请看/etc/cron.d/路径下的文件)。放到/etc/cron.daily、/etc/cron.weekly、/etc/cron.monthly下面的文件是由anacron执行的。而anacron执行方式是在/etc/cron.hourly/0anacron里面。 - crond预设有三个地方会有执行脚本配置文件,分别是
/etc/crontab,/etc/cron.d/*,/var/spool/cron/*。 - 当执行项目有输出时,该数据会mail给MAILTO设定的账号,所以如果不是很重要,将输出重定向到/dev/null中。
- 建议个人的话使用
crontab -e来创建定时任务,系统维护人员直接使用vim /etc/crontab,开发的软件使用vim /etc/cron.d/newfile。
crontab [-u username] [-l | -e |-r]
-u 只有root可以使用这个参数。
-e 编辑crontab的工作内容
-l 查阅crontab的工作内容
-r 移除所有的crontab的工作内容,如果只移除一项,可以用-e编辑。
- 每项工作的格式都是具有六个字段,这六个字段的意义为:
| 分钟 | 小时 | 日期 | 月份 | 周 | 指令 |
|---|---|---|---|---|---|
| 0-59 | 0-23 | 1-31 | 1-12 | 0-7(0和7都表示星期天) | 指令 |
- 特殊符号
| 特殊符号 | 意义 |
|---|---|
| * | 代表任何时刻 |
| , | 代表该字段有多个参数,如每天3点和6点执行命令,为0 3,6 * * * command |
| - | 表示一段时间范围内,如8点到12点之间每小时的20分都进行一项工作,20 8-12 * * * command |
| /n | n代表数字,表示每隔n单位的时间执行一此,如每隔5分钟执行一次,*/5 * * * * command,也可以写成0-59/5 * * * * command |
/etc/crontab
#使用哪种shell接口
SHELL=/bin/bash
#执行文件搜寻路径
PATH=/sbin:/bin:/usr/sbin:/usr/bin
#有输出时发给谁
MAILTO=root
#该文件中需要指定用户
1 * * * * * username command
anacron #
-
/etc/cron.daily各字段含义:- 天数:anacron 执行当下与时间戳 (/var/spool/anacron/ 内的时间纪录文件) 相差的天数,若超过此天数,就准备开始执行,若没有超过此天数,则不予执行后续的指令。
- 延迟时间:超过天数导致要执行定时任务,延迟执行的时间。
- 工作名称定义:通常与后续的目录资源名称相同即可。
- 实际要进行的指令串。
-
anacron执行流程(cron.daily):
- 由 /etc/anacrontab 分析到 cron.daily 这项工作名称的天数为 1 天;
- 由 /var/spool/anacron/cron.daily 取出最近一次执行 anacron 的时间戳;
- 由上个步骤与目前的时间比较,若差异天数为 1 天以上 (含 1 天),就准备进行指令;
- 若准备进行指令,根据 /etc/anacrontab 的设定,将延迟 5 分钟 + 随机n分钟 (看RANDOM_DELAY 的 设定);
- 延迟时间过后,开始执行后续指令,亦即『 run-parts /etc/cron.daily 』这串指令;
- 执行完毕后, anacron 程序结束。
free、uname、hostname、locale查看和设置系统信息 #
-
free -h查看内存使用情况。 -
uname [-asrmpi]-a表示所有;-s 系统核心名称;-r 核心的版本;-m 本系统的硬件名称(x86_64);-p CPU的类型;-i 硬件的平台。 -
uptime显示系统启动时间和工作负载。 -
hostnamectl [set-hostname 主机名]修改主机名。 -
timedatectl [list-timezones | set-timezone | set-time | set-ntp]列出系统上的失去、设定时区、设定时间、设定网络校时。 -
localectl set-locale LANG=en_US.utf8设置语系。通过locale -a可以查看linux支持了多少语系,通过locale来查看系统目前的语言环境。LC_ALL、LC_CTYPE、LANG这三个环境变量的值决定了操作系统当前使用的是哪种字符集,优先级是LC_ALL>LC_CTYPE>LANG。 -
硬件数据收集:dmidecode(CPU型号、主板型号、内存相关型号等), gdisk, dmesg, vmstat(分析cpu、内存、io目前的状态), lspci, lsusb,iostat。
ls 列出文件 #
- ls 列出指定的目录下的文件
-d 目录名列出目录名而不进入该目录。
cat、tac、tail、wc 查看文件 #
- cat:从第一行开始显示文件内容
-n标上行号
- tac:从最后一行开始显示
- nl:显示的时候输出行号
- more:一页一页的显示文件内容
- less:与more类似,但是可以往前翻
/srting,向下搜索string?string,向上搜索string
- head:只看头几行
- 默认是显示10行
head -n -100 filename文件后面100行不显示
- tail:只看尾几行
- 默认是显示10行
tail -f filename文件内容如果有增加,输出增加的内容-n num filename输出文件末尾的n行,默认是10行tail -n +100 filename文件第100行(包括)以后都会被列出来
- od:以二进制查看
- file:查看文件类型
- wc:查看文件里有多少字,多少行,多少字符。
- wc [-lwm] -l表示列出多少行,-w表示列多多少字,-m表示列出多少字符。
重定向与管道 #
- 标准输入
<<或<;标准输出>>或>;标准错误输出2>或2>>。 >会覆盖原文件,>>会追加到文件中。如find /home -name .bashrc > list_right 2> list_error,将正确输出和错误输出存入到不同的文件中。- 黑洞装置
/dev/null,可以吃掉任何导向这个装置的信息。 - 将正确和错误输出都放到同一个文件中
find /home -name .bashrc > list 2>&1。对2>&1的理解,这里2表示错误输出,意思是将错误输出重定向到标准输出,&1表示对标准输出的应用。 - 管道
|只会处理标准输出,会忽略标准错误输出。 - 管道命令必须要接收上一个指令的标准输入,如less、more、head、tail时管道命令,而如ls、cp、mv就不是管道命令。
- 管道后面第一个必须是指令。
- 在管道中常常会使用前一个指令的输出作为后一个指令的输入,某些指令需要指定文件名来处理,该stdin和stdout可以使用
减号"-"来替代。如tar -cvf - /home | tar -xvf - -C /tmp/homeback,这个命令是将/home里的文件打包,将打包的文件输出到stdout,后面的命令从stdin读取数据,所以我们就不需要文件名了,直接使用-代替。 xargs [OPTION] COMMAND [R]:读入stdin的数据,并以空格符作为分割,将stdin分割成参数。xargs -n 1表示每次执行指令值取一个参数。xargs -I R将从标准输入获取到的数据替换后面命令的参数R。xargs -i相当于xargs -I {}。(man手册里面不建议再使用-i了)- xargs的-I {}必须要放到-n前面。
- 例:
ls *.jar | xargs -I {} -n 1 sh start.sh {}
grep 查找指定内容 #
-
grep [-invAB] ‘搜索字符串’ filename:查找文件或标准输出中的字符串,
- -i表示忽略大小写。
- -n表示输出行号。
-v:表示选择未匹配的行(反选)。- -A:–after-context,输出查找字符串后面n行。
- -B:–before-context,输出查找字符串前面多少行
- -r:递归查找当前路径下的包含指定内容的文件,同时输出包含此内容的行,-l只输出文件名。如查找指定路径下包含auth的文件:
grep -rl auth。 - -F: 将搜索模式当作纯文本字符串处理,禁用正则表达式的特殊字符解析,可以很方便的搜索字符串中有空格的情况
grep -Fi "BIOS LOG" file.txt。
whereis、which、locale 查找文件 #
-
whereis:针对几个特定目录查找文件,
whereis -l查看这几个特定目录。 -
which:根据PATH查看可执行文件。
-
locate:根据/var/lib/mlocate内的数据库记载搜索文件(数据库未更新前搜索某新建的文件可能搜不到)。
find:查找工具 #
-
用法
find [PATH] [option] [action],PATH可以是多个目录,find查找会进入子目录。- 查看/home下3天内有修改的文件
find /home -mtime 3(如果是+3表示大于等于3天前的文件名,-3表示小于等于3天内的文件名); - 查看/home下属于bes的文件
find /home -user bes,查看不属于任何人的文件find / -nouser; - 查到/home下文件名包含了passwd的文件名
find /home -name "*passwd*"; - 查看/home下文件类型为普通文件的文件名
find /home -type f; - 查看文件权限大于755的文件名
find -perm /755; find / -perm /7000 -exec ls -l {} \;其中{}表示find找到的内容会放到{}中;-exec到;是关键字,表示开始和结束。- find查找会直接去查找磁盘,可能比较慢。
- 查看/home下3天内有修改的文件
tar 压缩与解压工具 #
tar -xzvf xxx.tar.gz解压文件- -x extract提取文件;-z通过gzip处理文件;-v:verbose显示执行过程;-f指定文件名
tar -cvzf 生成的文件名.tar.gz dir/压缩文件- -c:create生成文件
- tips:-C(大写)将文件放到指定文件夹
tar- -c建立打包文件;-v查看执行过程;-x解压缩;-t查看打包文件内的情况;-C在特定目录解压缩;-z使用gzip解压缩;-j使用bzip2解压缩;-J使用xz解压缩;-f后面要立刻接上要被处理的文件名;-p保留备份数据原本权限与属性;–exclude=FILE压缩过程中不打包FILE。
gzip -[cdv#]:-c将压缩的数据输出到屏幕;-d解压缩;-v显示出原文件/压缩文件的压缩比等信息;-#表示数字,-1最快但压缩比最差,-9最慢但压缩比最慢,-6是默认。使用gzip压缩时,原文件会被压缩为***.gz,原文件就不存在了。bzip2 -[cdkzv#]:-c将压缩的数据输出到屏幕上;-d解压缩;-k保留源文件;-z压缩(默认,可不加);-v显示压缩比等信息;-#与gzip一样。文件名是xxx.bz2。xz [-dtlkc#]:-d解压缩;-t测试压缩文件完整性;-l列出压缩文件相关信息;-k保留原文件不删除;-c数据输出到屏幕上;-#和bzip2一样。-T0指定线程数量和CPU的数量一样。
useradd、passed、usermod、userdel 用户账号管理 #
- 默认情况下所有的系统上的账号和一般身份使用者,都记录在/etc/passwd这个文件中,个人密码记录在/etc/shadow文件下,所有组名都记录在/etc/group中。
- 当输入账号密码登陆后,系统先1. 寻找/etc/passwd里面是否有输入的账号,有的话读取UID和GID以及该账号的home目录和shell;2. 进入/etc/shadow找出对应的账号与UID,然后和对密码是否相符;3. shell启动。
- 查看已登录系统上的用户,可以使用
who。
/etc/passwd #
- 每一行都代表一个账号,有几行就代表有几个账号在系统中。里面有很多账号本来就是系统正常运行所必需的,可以称之为系统账号。
#①账号名称:②x:③UID:④GID:⑤用户信息说明:⑥home目录:⑦shell
root:x:0:0:root:/root:/bin/bash
#账户名称需要和UID对应,UID就是使用者标识符,UID中0表示系统管理员;1~999表示系统账号(1~200表示系统自行建立的系统账号);1000~60000就是给一般使用者使用的。一个UID可以包含多个用户
#早期unix密码放在此文件中,后来放到了/etc/shadow中,这里用x替代。
#GID与/etc/group有关。
#当用户登陆系统后就会取得一个shell来与核心沟通。
/etc/shadow #
#账号名称:密码:最近密码变动的日期:密码不可被更改的天数:密码需要修改的天数:密码需要变更前的警告天数:密码过期后多少天内还有效:账号失效日期:保留字段
#第四个字段的0表示随时都可以修改密码
root:$6$xtr:18894:0:99999:7:::
/etc/group #
#组名:x:GID:此群组支持的账号名称
#每个用户都可以有多个群组
root:x:0:dmtsai,alex
- 在/etc/passwd中有个GID,即初始群组,初始群组不会加在/etc/group的第四个字段。
- 使用
groups命令可以获取当前账号所有的群组,输出的第一个群组为有效群组,新创建的一个文件使用的就是有效群组。通过newgrp xxx来切换有效群组。 - 相关命令:
groupadd groupmod groupdel
useradd #
-g 初始群组该字段会被添加到/etc/passwd第四个字段。-u UID -G 次要群组 -c 说明信息(/etc/passwd第五个字段) -r 系统账号 -s /bin/bash(指定一个初始的shell)。- -M 不建立home目录(系统账号默认) ;-m 建立home目录(一般账号默认)。
- useradd参考的是/etc/default/useradd文件,默认值可以通过
useradd -D查看;除此之外,还参考了/etc/login.defs文件。 - 相关命令:
id chsh
passwd #
- 使用useradd建立了账号后,默认情况下无法使用该账号登陆,需要使用passwd设定密码。
-llock,会在/etc/shadow第二栏最前面加!使得密码失效,-uunlock,与-l相反;-S列出秘密相关参数;-n多久不可修改密码;-x多久内必须修改密码;-w密码过期前多少天开始警告 ;-i密码失效日期;--stdin从控制台获取输入。- 其他命令
chage -l user。
usermod #
- 修改账号的数据。
- 添加群组
usermod -a -G wheel koal
userdel #
- 删除用户的相关数据。
-r表示同时删除该用户的home目录。
chgrp、chown、chmod 文件权限 #
-
chgrp [-R] 文件/文件夹改变文件的群组(必须是/etc/group中存在的)。 -
chown [-R] name:groupname 文件或目录来修改文件的拥有者,-R表示递归。 -
chmod [-R] 文件/目录改变文件/目录的权限。
su 切换用户 #
su单纯使用su切换为root身份时,表明切换为root身份。读取变量的设定方式为non-login shell的方式,这种方式很多原本的变量不会改变。su - username使用该命令代表使用login-shell的变量文件来登入系统。su - -c 指令执行一次root的指令。
sudo 以其他用户执行指令 #
-
sudo并非所有人都能执行sudo,只有/etc/sudoers内的用户能执行sudo这个指令。sudo [-u 用户] 指令以某个用户的身份执行指令。不加该参数表示使用root执行指令。- sudoers文件格式1:
使用者账号 登入者的来源主机名=(可切换的账号) 可下达的指令。可下达的指令必须使用绝对路径。 - sudoers文件格式2:
%群组 ALL=(ALL) ALL - sudoers文件格式3:
%群组 ALL=(ALL) NOPASSWD:ALL - sudoers文件格式4:
myuser1 All=(root) !/usr/bin/passwd, /usr/bin/passwd [A-Za-z]*,!/usr/bin/passwd root。表示myuser1可以执行除了passwd和passwd root外的所有指令。 - 创建别名:
#别名必须大写 User_Alias ADMPW=pro1,pro2,pro3 myuser1,myuser2 Cmd_Alias ADMPWCOM=!/usr/bin/passwd, /usr/bin/passwd [A-Za-z]*,!/usr/bin/passwd root ADMPW ALL=(root) ADMPWCOM #可以使用sudo搭配su,将用户身份转换为root ADMPW ALL=(root) /bin/su -- sudo时间间隔为5min。
ulimit 限制系统资源 #
ulimit限制用户的某些系统资源(比如可以开启的文件数量)
ulimit -[SHacdfltu] [配置]
-H #hard limit,严格的限制,必定不能超过这个设定的数值
-S #soft limit,警告的设定,可以超过这个设定值,但超过则有警告。
-a #可列出所有的限制,-标识没有限制。
-f #此shell可以建立的最大文件大小,单位为KB。
-t #可使用的最大CPU时间,单位为秒。
-u #单一用户可以使用的最大程序的数量。
-d #程序可以使用的最大segment容量。
-l #可用于锁定(lock)的内存量。
#一般身份如果设置了ulimit的值,通过注销再登录即可恢复,也可以重新设定
#限制只能建立10MB以下容量的文件
ulimit -f 10240
limits.conf
#文件详细描述
vbird1 soft fsize 90000
#第一个字段为账号,或者为群组,如果是群组需要加上@。如果使用群组,这个功能只对初始群组有效。
#第二个字段为限制的模式,是严格hard还是警告soft。
#第三个字段为限制,比如是限制文件容量等。
#第四个字段为限制的值
#限制prol这个群组每次只能有1个用户登录
@prol hard maxlogins
#文件修改后需要重新登录才会有效。
ACL #
- Access Control List,用来提供在owner、group,others的rwx之外的权限设定,可以针对单一使用者,单一文件或目录来进行rwx的权限规范。
#检查系统是否支持ACL
dmesg | grep -i acl
#设定acl参数
setfacl[-bkRd] [{-m | -x} acl参数] 目标文件名
-m : 设定acl参数给文件使用
-x : 删除后面的acl参数
-b : 移除所有的acl参数设定
-k : 移除预设的acl参数
-R : 递归设定acl
-d : 设定预设的acl参数,只对目录有效,在该目录新建的数据都会引用此默认值
#为xiaoxiang用户设定文件的权限为rwx
#一个文件设定了ACL参数后,他的权限部分就会多出来一个+号。
setfacl -m u:xiaoxiang:rwx file1
#为文件使用者设定权限
setfacl -m u::rwx file2
#为群组设置权限
setfacl -m g:mygroup:rx file3
#为目录设置acl权限,未来文件的acl权限都继承此目录
setfacl -m d:u:xiaoxiang:rx /home/xiaoxiang/dir1
#让xiaoxiang无法使用该目录
setfacl -m u:xiaoxiang:- /home/xiaoxiang/dir2
#取消某个账号的ACL权限设定
setfacl -x u:xiaoxiang /home/xiaoxiang/file5
#获取file1的acl权限内容
getfacl file1
#结果中#开头的表示默认值
#结果中的mask表示用来规范最大允许权限
df和du #
df查看文件系统的的信息。df -h查看所有文件系统的信息。df -T查看所有文件系统的类型。df -iT查看所有文件系统的类型和inode的数量。
du [-hskm] 文件或目录名称统计磁盘的使用情况。- -h 易读的方式显示。默认情况下会递归展示目录,但不会展示文件。
- -s (summarize)列出总量。
- -d (–max-depth=N):N表示深度,1表示输出子文件夹的大小,2表述输出子文件夹的子文件夹的大小。
- -a (–all) 不加该参数表示只统计文件夹,加该参数表示统计所有文件。
- -k和-m 以kB/mB显示。
lsblk 列出磁盘列表 #
-f列出磁盘内文件系统的名称。-d仅列出磁盘本身,不会列出分区。- 输出信息介绍
- NAME装置的文件名
- MAJ:MIN 主要:次要装置代码
- RM 是否为可卸载装置 removable device
- SIZE 容量
- RO 是否为只读装置
- TYPE 是磁盘disk、分区槽partition还是只读存储器rom
- MOUNTPOINT 挂载点
mount 磁盘挂载 #
-
mount [-alt]LABLE=''/UUID=''/装置文件名 挂载点/umount挂载与卸载mount /dev/sda2 /d将/dev/sda2挂载到/d。umount [-f] 挂载点或装置文件名-f强制删除。- -n 不写入/etc/mtab。
- -o后面可以跟一些挂载时额外加上的参数;1. asyn,sync 此文件系统是否使用同步写入(sync)或异步(async)的内存机制。默认为async。2. atime,noatime 是否修订文件的读取时间。3. ro,rw 挂载文件系统为只读或可写。auto,noauto 允许此文件系统被以mount -a自动挂载(auto)。4. dev,nodev 是否允许此文件系统上可建立装置文件。5.suid,nosuid 是否允许此文件系统上有suid的文件格式。6. ecex,noexec 是否允许此文件系统上有可执行文件。7. user,nouser 是否允许此文件系统让任何使用者执行mount,一般mount只有root可以进行,但下达该命令后,一般user也能对其进行挂载。8. defaults 默认为rw,suid, dev,exec,auto,nouser,async。9. remount 重新挂载。
- -a 依照配置文件/etc/fstab的数据将所有未挂载的磁盘挂载。
- -t 要挂载的文件系统的类型。
-
开机挂载(修改/etc/fstab[filesystem table])
- 参数格式:装置/UUID/LABEL 挂载点 文件系统 文件系统参数 dump fsck
- 例:UUID=XXX(使用blkid查询) /d ntfs defaults 0 0
- /etc/fstab是开机时的配置文件,实际的filesystem的挂载记录到/etc/mtab和/proc/mounts这两个文件中。
-
sh -c "xxx"将一个字符串作为完整的命令来执行。 -
history n用来查询过去执行的指令,n表示显示最近n个命令。bash会记录使用过的指令,默认记录1000个,指令存放位置在~/.bash_history中。该文件会记录上一次登录之前的指令,而这一次登录所执行的指令都存在内存中,当注销后,这些指令才会记录到.bash_history中。 -
使用write可以给linux上的其他用户发消息,通过
who可以查看目前有谁在线。通过write koal给所有以koal登录的用户发消息。通过mesg n来关闭接收消息,但无法拒绝root的消息。通过mesg y来开启接收消息。使用wall可以对系统上所有的用户发送消息wall "hello world"。
man(manual)用户手册 #
- man中有几个常用的数字的含义:1 用户在shell环境中可以操作的指令或可执行文件;2. 系统调用,如
man 2 open;3. 函数库调用;4. 特殊文件,如man 4 tty;5 配置文件或者某些文件的格式;6. 游戏;7. 杂项;8 系统管理员可用的指令。例:man 8 sudo;9. 内核例程。 - man page一般包含:①NAME:简短的说明;②SYNOPSIS:简短的指令下达语法说明;③DESCRIPTION:较完整的说明;④OPTIONS;⑤COMMANDS:当这个程序执行的时候,可以在此程序中下达的指令。⑥FILES:关联的文件;⑦SEE ALSO:其他可以参考的信息;⑧EXAMPLE:一些可以参考的范例。
- 快捷键:空格键:向下翻一页 [Page Up]:向上翻一页 [Page Down]:向下翻一页 [Home]:去第一页 [End]:去最后一页 /string:向下搜索string ?string:向上搜索string n/N:n表示下一个搜索,N表示上一个搜索。
SELinux #
- 全称是Security Enhanced Linux。SELinux是在进行进程、文件等细部权限设定依据的一个核心模块。SELinux提供了一些预设的策略(Policy),并在政策内提供了多个规则(rule)。
- 自主式访问控制(Discretionary Access Control,DAC)是根据进程的拥有者与文件资源的rwx权限来决定有无存取的能力。
- 委任式访问控制(Mandatory Access Control,MAC)可以根据特定的进程和特定的文件资源来进行权限的管控,即使是root,在使用不同的进程时,取得到的权限不一定是root,而要看当时进程的设定而定。控制的主体由使用者变成了进程。
- SELinux是通过MAC的方式来管控进程,控制的主体是进程,而目标是该进程能否读取的文件资源。
- 主体(Subject):即进程。
- 目标(Object):主体目标能否存取的目标资源,一般就是文件系统。
- 策略(Policy):由于进程和文件数量庞大,SELinux会依据某些服务来制定基本的存取安全性策略,这些策略中由详细的规则(rule)来指定不同的服务开放某些资源的存取与否。Linux里提供了三个主要的策略,分别是:
- targeted:针对网络服务限制多,针对本机限制少,是预设的策略。
- minimum:仅针对选择的进程来保护。
- mls:完整的SELinux限制,限制较为严格。
- 安全性本文(security context):主体能不能存取目标除了策略指定外,主体和目标的安全性本文必须一致才能够顺利存取,安全性本文类似于文件系统的rwx。
- 主体如果要存取目标,首先需要通过SELinux政策内的规则;其次与目标资源的安全性本文对比;最后再检查目标的rwx权限。
安全性文本 #
- 文件的安全性文本是放到文件的inode内的,可以使用
ls -Z去观察安全性文本。 - 安全性文本主要用冒号分为三个字段。
identify:role:type。 - 身份识别(Identify),常见的有:
- unconfined_u:不受限的用户,也就是说该文件来自于不受限的进程所产生的。
- system_u:系统用户,大部分就是系统自己产生的。
- 基本上如果是系统或软件本身所提供的文件,大多就是system_u这个身份名称,如果是用户透过bash自己建立的文件,大多数是不受限的unconfined_u,如果是网络服务所产生的文件,或者是系统服务运作过程中产生的文件,大部分的识别就会是system_u。
- 角色(Role)
- object_r:代表的是文件或目录等文件资源。
- system_r:代表的就是进程。
- 类型(Type),一个主体进程能不能读取到资源,与类型有关,类型在文件和进程中的定义不太相同。在文件资源上称为类型Type,在进程上称为领域domain。
SELinux三种模式的启动、关闭和观察 #
- SELinux目前共有三种模式,分别为:
- enforcing:强制模式,代表SELinux正确的开始限制domain/type了。
- permissive:宽容模式,表示不会实际限制domain和type,但会有警告信息。
- disable:关闭,代表SELinux并没有实际运作。
#获取当前的SELinux模式
getenforce
#查询当前的策略
sestatus
#修改策略,修改/etc/selinux/config的SELINUX=enforcing
#SELinux在enforcing和permissive之间切换无需重启
#切换到disable或者从disable切换到其他需要重启
setenforce [0|1] #0表示permissive,1表示Enforcing