2021-03-11
- online analytical processing of queries(OLAP):联机分析
- clickhouse是一个用于OLAP的列式数据库管理系统(来自同一列的数据被存储在一起)。
sudo service clickhouse-server start启动clickhouse.- clickhouse不要求主键唯一
clickhouse连接客户端
#
clickhouse-client
#
-
clickhouse-client命令行参数
clickhouse-client配置文件地址(使用以下第一个配置文件)
- 通过
--config-file参数指定
./clickhouse-client.xml~/.clickhouse-client/config.xml/etc/clickhouse-server/config.xml
mysql
#
- 可以通过mysql命令工具连接,需要在配置文件中配置mysql_port:
<mysql_port>9004</mysql_port>
- 使用命令行工具mysql进行连接:
mysql --protocol tcp -u default -P 9004
数据库引擎
#
mysql引擎
#
表引擎
#
merge tree
#
-
MergeTree:设计用于插入大量数据当一张表当中。数据可以以数据片段的形式一个接一个的快速写入,数据片段在后台按照一定的规则进行合并。
-
SummingMergeTree:合并SummingMergeTree表的数据片断时,clickhouse会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
-
ReplacingMergeTree:该引擎会删除排序键值相同的重复项。适用于在后台清除重复的数据以节省空间,但不保证没有重复数据出现。在数据合并的时候,如果制定了Replcaing的参数,当参数未指定,则保留最后一条数据,当参数已指定,则保留ver值最大的版本。数据的去重只会在数据的合并期间进行,所以常常今天数据重复了,明天看数据还没有被去重。
-
AggregateMergeTree:改变了数据片段的合并逻辑。clickhouse会将一个数据片段内所有具有相同主键的行替换为一行,这一行会存储一系列聚合函数的状态。可以使用AggregatingMergeTree表来做增量数据的聚合统计,包括物化视图的数据聚合。
-
CollapsingMergeTree:会异步的删除掉所有字段的值都相等(除了列Sign,该列一个为1,一个为-1)的成对的行,下面这两行就会被删除。
-
| UserId |
PageViews |
Duration |
Sign |
| 123 |
5 |
146 |
1 |
| 123 |
5 |
146 |
-1 |
-
1是状态行,-1是状态取消行
-
VersionedCollapsingMergeTree:用于相同目的的折叠树但使用了不同的折叠算法,允许以多个线程的任何顺序插入数据。Version列有助于正确折叠行,即使他们以错误的顺序插入。而CollapsingMergeTree只允许严格的连续插入。
MergeTree
#
-
数据可以以数据片段的形式一个接一个的快速写入,数据片段在后台按照一定的规则进行合并。
-
存储的数据按主键排序;支持数据分区(如果指定分区键的话);支持数据副本;支持数据采样。
-
建表(
更多介绍看这里)
-
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2]
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|to volume 'xxx'],...]
[SETTINGS name=value,..]
-
ENGINE:引擎名和参数
-
ORDER BY:排序键,可以是一组列的元组或任意的表达式。如果没有用PRIMARY KEY显式指定主键,clickhouse会使用排序键作为主键,如果不需要排序,可以使用ORDER BY tuple()
-
PARTITION BY:分区键,要按月分区,可以使用表达式toYYYYMM(date_column),这里date_column是一个Date类型的列,分区的格式会是YYYYMM
-
PRIMARY KEY:主键,如果要选择与排序键不同的主键,可选。大部分时间不需要再专门指定一个primary key
-
SIMPLE BY:用于抽样表达式,如果要用抽样表达式,主键中必须包含这个表达式。如SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))
-
TTL:可以为表设置,也可以为每个列单独设置
- 表TTL:表可以设置一个用于移除过期行的表达式,当表中的行过期时,clickhouse会删除所有对应的行。clickhouse在数据片段合并的时候会删除掉过期的数据,如果在合并的过程中执行SELECT查询,则可能得到过期的数据。
-
SETTINGS:控制MergeTree行为的额外参数
-
数据存储
- 表由按主键排序的数据片段组成。
- 当数据被插入到表中时,会创建多个数据片段并按主键的字典排序。
- 不同分区的数据会被分成不同的片段,clickhouse在后台合并数据片段以便更高效存储。合并机制不保证具有相同主键的行全部合并到同一个数据片中。
- 数据片段以wide或compact格式存储。wide格式下,每一列都会在文件系统中存储为单独的文件,compact模式下所有列都存储在同一个文件下。
- 每个数据片段被逻辑分割成颗粒。颗粒是进行数据查询时最小的不可分割数据集。每个颗粒都包含整数个行。
-
可以使用ORDER BY tuple()创建没有主键的表,这种情况下,clickhouse会根据数据插入的顺序存储。
-
对于select查询,如果where子句中有下面这些表达式,就可以使用索引
- 包含一个与主键/分区键中的部分字段或全部字段相等或不等的表达式。
- 主键/分区键 in (xxx,xxx,xxx) 或者 主键/分区键 like ‘xxx’。
- 基于主键/分区键的字段上的某些函数。
- 基于主键/分区键的表达式的逻辑表达式。
-
TTL
- TTL表达式的计算结果必须是日期或日期时间类型的字段
MergeTree这一块越看越迷惑,之后再来接着看吧。
日志引擎
#
- 是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的。
该引擎的共同属性
#
- 写入时将数据追加到文件末尾。
- 不支持索引。
- 非原子地写入数据。
- Log和StripeLog支持并行读取数据,Log引擎将表中的每一列使用不同的文件;StripeLog将所有的数据存储到一个文件中
2021-03-11
python基础
#
数据类型和变量
#
- 整数:可以是任意大小
- 浮点数:除了小数外还可以用科学计数法:1.23e9
- 字符串:以
"或'括起来的文本,python允许使用r''表示引号内部的字符串默认不转义,python允许用'''...'''的格式表示多行内容
- 布尔值:
True或False,可以进行and or not运算
- 空值:
None,不等于0
- 列表list:如
classmate=['xiaoming','lihua',123,True],list是一个可变的有序表。
- 可以使用append函数追加到末尾
- 可以使用insert(i,参数)插入到指定位置
- 删除末尾元素使用pop(),删除指定位置元素用pop(i)
- 元组tuple:
classmate=('xiaoming','lihua',123,True),一旦初始化就不能修改
- 当只有一个元素要这么定义:
classmate=('hel',)
- 字典dict:
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}键值对
- 可以通过get(key)或d[key]获取值
- 可以通过d[key]=xxx直接赋值
- 可以通过pop(key)删除键值对
- 可以通过in判断key是否存在
- key必须是不可变对象
- set:要创建一个set,需要一个list作为输入集合,
- set是一组key的集合,无序,不重复。
- add(xxx)可以向set里面加元素,remove(xxx)可以删除元素
- 变量:可以把任意类型数据赋值给同一个变量(不同类型也可以)
- 常量:用全大写的变量名表示常量是一个习惯上的用法。
- 除法:python中有两种除法,一种是
/:计算结果是浮点数,一种是 //:计算结果是整数(这种称为地板除),python还提供了余数运算:%
字符串和编码
#
- 在计算机内存中,统一使用unicode编码,当需要保存到硬盘或者传输的时候,就会转化为UTF-8编码
- 用记事本编辑时,从文件中读取的UTF-8会被转化为Unicode字符到内存中
- python3字符串是以unicode编码的,可以通过
ord()获取字符串的整数表示,chr()把编码转换为对应的字符
- 当这么写时->
b'ABC'表示bytes类型,每个字符只占一个字节。
- 以Unicode表示的字符串通过ecnode()方法可以编码位指定的bytes,如
'中文'.encode('utf-8')
len('xxx')可以知道包含了几个字符。
结构
#
选择结构:非0,非空字符串、非空list就表示True
#
age = 3
if age >= 18:
print('adult')
elif age >= 6:
print('teenager')
else:
print('kid')
循环结构
#
sum = 0
#0~100
for x in range(101):
sum = sum + x
print(sum)
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
#break和continue也有
函数
#
- python内置了很多函数,可以直接调用,如print、input、len、max、int、float、str、bool等
def my_abs(x):
if x >= 0:
return x
else:
return -x
#空函数,pass也可用在其他地方,如if里面
def nop():
pass
- 可以返回多个值,会转化成tuple
- 函数参数中可以设置默认参数,必选参数必须放在默认参数前面
- 可以不按顺序提供部分默认参数,但要把参数名写上
- 定义可变参数是在参数前面增加一个*,如
def calc(*numbers)
- 当已经有了list或tuple,要调用一个可变参数,可以
calc(*nums)
- 关键字参数:
def person(name, age, **kw):会在函数内部自动组装成一个dict
- 可以传入多个键值对,也可以传入一个dict(
person('Jack', 24, **extra))
- 命名关键字参数:
def person(name, age, *, city, job):
- 调用方式
person('Jack', 24, city='Beijing', job='Engineer')
- 命名关键字参数必须传入参数名
- 上面这些都可以组合
其他
#
- 切片:
L[:2]切出下标为0和1的元素
- for in可用来迭代,判断是否可迭代可以用collections的Iterable类型判断。
isinstance('abc',Iterable)
- range(1:10)可用来生成1到9
- 列表生成器
[x*x for x in range(1,11) if x%2==0]
- 赋值语句
a, b = b, a是通过tuple实现的,相当于t = (b, a) a = t[0] b = t[1]
- 凡是可以作用于for循环的对象都是Iterable类型,凡是可作用于next()函数的对象都是Iterator类型
- 函数也是一个对象,函数对象可以赋值给变量。
- 任何代码的第一个字符串都被视为模块的文档注释,
__author__变量可以把作者写进去
- 导入模块
import sys,sys的argv变量用list存储了命令行的所有参数,argv的第一个参数是py文件的名称
- 类似
__xxx__的变量是特殊变量,类似_xxx_和_xxx的变量是非公开变量(private)。
- 命名类用UpperCamelCase(第一个字母大写,后面采用驼峰命名法),命名函数和方法采用lowercase_with_underscores(小写带下划线),
2021-03-02
head
#
-
<meta>:元数据就是描述数据的地方
-
<meta charset="utf-8">:指定文档中字符的编码。
-
添加作者描述和该网页的描述,这些数据会被搜索引擎解析。
<meta name="author" content="xiaoxiang">
<meta name="description" content="A learning notes,about java,git,etc"
<meta name="keywords" content="xxx">:keywords关键字已不再使用了。因为该关键字是提供给搜索引擎,搜索引擎根据不同的关键字找到相关网站,但是有些网站填充了大量的关键字到keyword,错误的引导了搜索结果。
-
<link rel="shortcut icon" href="favicon.ico">:添加网页图标
-
<link rel="stylesheet" href="index.css">:添加样式表
-
<html lang="zh-CN">:为站点设置语言,如果该项设置了,网站就会被搜索引擎更好的索引(如允许他在不同的语言中正确显示)。也可在在其他标签中设置该属性<span lang="en">小象</span>。
body
#
<em>:emphasis斜体显示。<a href="mailto:example@example.com,exp@exp.com?cc=exp2@exp2.com&subject=hello&body=hi">向example和exp发邮件</a>当点击一个链接或按钮时,打开一个新的电子邮件发送信息而不是连接到一个资源(邮件地址可为空,表示打开电子邮件),cc表示抄送,subject表示主题,body表示主体,每个字段的值必须是URL编码的,即不能有非打印字符,中文要转意成%xx的形式。- 列表
<ol>:ordered list<ul>:unordered list<dl>:description list<li>:list item<dt>:description term<dd>definition description
<abbr>:Abbreviation缩写 例:我们使用HTML来组织文档。<address>:标记联系方式的元素。<code> <pre> <var> <kbd> <samp>:用于展示计算机代码。<time datetime="2021-03-10">2021年3月10日</time>:标记时间,可供机器识别格式。- 一个block形式展现的块级元素不会被嵌套进内联元素中,但可以嵌套在其他块级元素中。
https://developer.mozilla.org/zh-CN/docs/Learn/HTML/Introduction_to_HTML/Document_and_website_structure
2021-02-28
HTTP概述
#
- HTTP是一种client-server协议,由客户端发出的消息叫request,被服务端响应的消息叫response。
HTTP能控制什么
#
一、缓存
#
- 常见的HTTP缓存只能存储GET响应。缓存的关键主要包括request method和目标url。
缓存控制(HTTP/1.1定义的Cache-Control)
#
Cache-Control:no-store :没有缓存。缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。Cache-Control:no-cache:缓存但重新验证。此方式下,每次有关请求发出时,该请求会带有与本缓存相关的验证字段,服务端会验证请求中所描述的缓存是否过期,如未过期(返回状态码304),则使用本地缓存副本。Cache-Control:private|Cache-Control:public :私有和公共缓存。private表示该响应是专用于某个用户的,中间人不能缓存此响应;public表示该缓存可以被任何中间人缓存。Cache-Control:max-age=31536000:过期。表示资源能被缓存的最大时间,max-age是距离请求发起的时间的秒数。Cache-Control:must-revalidate:验证方式。must-revalidate意味着在考虑使用一个陈旧的资源时,必须先验证它的状态,已过期的缓存将不被使用。Pragme是HTTP/1.0定义的一个header属性,请求头中包含Pragme的效果与Cache-Control:no-cache相同,但是HTTP响应头中没有明确定义这个属性。
Vary响应
#
- Vary响应头决定了对后续的请求头,如何判断时请求一个新的资源还是使用缓存的文件。
- 当缓存服务器收到了一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能够使用缓存的响应。
二、开放同源限制
#
- 只有来自相同来源的网页才能够获取网站的全部信息。HTTP可以通过修改头部来开放这样的限制。
三、认证
#
- 一些页面能被保护起来,仅让特定的用户进行访问。基本的认证功能可以直接通过HTTP提供。
四、代理和隧道
#
- 通常服务器或客户端都是处于内网,对外网隐藏真实IP。因此HTTP请求就要通过代理越过这个网络屏障。
正向代理
#
- 也可以叫网关,它存储并转发网络服务(如DNS、网页)以减少和控制大家使用的带宽。
- 正向代理代表客户端,可以隐藏客户端的身份。
反向代理
#
-
反向代理代表服务器,可以隐藏服务器的身份。
-
作用:
- 负载均衡:在多个服务器之间分发负载,
- 缓存静态内容:缓存静态内容,为服务器分担压力,
- 压缩:压缩和优化内容以加快传输的速度。
-
代理可以将请求地址设置为自身的ip。
-
Forwarded(标准化版本)首部包含了代理服务器的客户端的信息。
- 语法:
Forwarded:by=<identifier>;for=<identifier>;host=<host>;proto=<http|https>
- identifier可以是:①ip地址;②语义不明的标识符;③unknown。
by=<identifier>该请求进入代理服务器的接口。for=<identifier>发起请求的客户端以及代理链中的一系列的代理服务器(这意味着要写多个for=)。host=<host>代理接收到的Host首部(Host请求指明了请求将要发送到的服务器主机名和端口号)的信息。proto=<http|https>表示发起请求时采用的何种协议。
-
X-Forwarded-For:在客户端访问服务器的过程中,如果需要经过HTTP代理或者负载均衡服务器,可以使用该参数来获取最初发起请求的客户端的IP地址。
- 语法:
X-Forwarded-For:<client>,<proxy1>,<proxy2>...。
- 第一个参数表示客户端的IP地址,如果一个请求经过了多个代理服务器,那么每一个代理服务器的IP都会被依次记录在内。
-
X-Forwarded-Host:用来确定客户端发起请求中使用Host指定的初始域名
Host:Host请求头指明了请求将要发送到的服务器的主机名和端口号,所有HTTP/1.1请求报文中必须包含一个Host头字段。
-
X-Forwarded-Proto:用来确定客户端与代理服务器或者负载均衡服务器之间连接所采用的传输协议。
HTTP报文
#
http请求组成
#
- 第一行包括请求方法及请求参数
- 接下来的行每一行都表示一个HTTP首部,为服务器提供关于所需数据的信息
- 一个空行
- 可选数据块,包含更多数据,主要被POST方法使用。
#一个http的动作,如下面的method
#要获取的资源路径,如下面的/chat
#HTTP协议版本号
GET /chat HTTP/1.1
#Headers,为服务器表达其他的信息
#Host指明了要发送到的服务器主机名和端口号,如果没有包含端口号,会自动使用请求服务的默认端口。
Host: xiaoxiang.space
#指明了client的应用类型,操作系统、软件开发商及版本号
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0
#告知服务器客户端可以处理的内容类型,采用mime来表示,;q=表示前面这个类型权重因子,没写就默认是1
Accept: application/json, text/javascript, */*; q=0.01
#客户端声明其能理解的自然语言
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
#会将客户端能够理解的内容编码方式通知给服务端。对应Content-Encoding
Accept-Encoding: gzip, deflate
#指示资源的MIME类型,下面这是post请求的默认格式
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
#加了这个就是ajax异步请求
X-Requested-With: XMLHttpRequest
#用来指明发送给服务器的消息主体的大小
Content-Length: 22
#指示了请求来自哪个站点。仅展示服务器名称,不包含任何路径。
#除了不包含任何路径,该字段与Referer类型。
Origin: https://developer.mozilla.org
#决定当前的事务完成后,是否会关闭网络连接,如果是keep-alive,网络连接就是持久的,使得对同一个服务器的请求可以继续在该连接上完成
Connection: keep-alive
#表示当前页面的来源页面的地址。如果当前页面采用的是非安全协议而来源页面采用的是安全协议时Referer不会被发送。
Referer: http://xiaoxiang.space/index
#是由先前服务器通过Set-Cookie首部投放并存储到客户端。
Cookie: JSESSIONID=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
#对于一些POST这样的方法,报文的body也包含了发送的资源
username=xxx&comment=xxx
HTTP响应组成
#
- 第一行是状态行,包括使用HTTP协议版本,状态码和一个状态描述。
- 接下来的每一行都表示一个HTTP首部,为客户端提供所发送数据的一些信息。
- 一个空行
- 最后一行是数据库,包含了响应的数据
#一个HTTP协议版本号
#一个状态码
#一个状态信息,我这个请求中居然没有???
HTTP/1.1 200
#HTTP headers
#用来向客户端发送cookie,expires表示过期时间
Set-Cookie: xiaoxiang.space=1; Max-Age=3600; Expires=Tue, 23-Mar-2021 11:21:23 GMT
Content-Type: application/json
#指明了将entity安全传递给用户的编码形式,chunked表示数据以一系列分块的形式发送,这种情况下不发送Content-Length。
Transfer-Encoding: chunked
#包含了报文创建的日期和时间。
Date: Tue, 23 Mar 2021 10:21:23 GMT
#需要将Connection首部设为keep-alive这个首部才有意义,可以设置超时时长和最大请求数。
#HTTP/2中Connection和Keep-Alive是被忽略的。
Keep-Alive: timeout=20
Connection: keep-alive
#下面是响应的数据
xxx
参考链接:
HTTP Headers - HTTP | MDN
- HTTP消息是服务器和客户端之间交换数据的方式,有两种类型的消息:请求和响应。
HTTP的连接管理
#
短连接
#
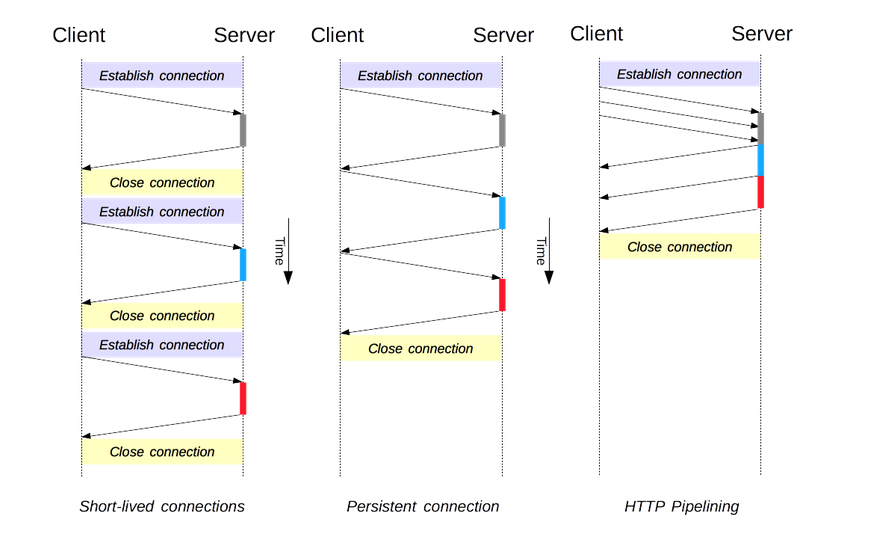
- HTTP/1.0的默认模型,每一次HTTP请求之前都会有一次TCP握手。在HTTP/1.1中,当
Connection被设为Close才会用到这个模型。
长连接
#
- HTTP/1.1中默认就是长连接,一个长连接会保持一段时间,重复用于发送一系列请求,节省了新建TCP连接握手的时间,这个连接会在空闲一段时间后关闭(通过设置
Keep-Alive来指定一个最小的连接保持时间),长连接会消耗服务器资源(毕竟是TCP)。
流水线
#
- 默认情况下HTTP请求是按顺序发出的,下一个请求只有在当前请求收到应答后才会被发出。而流水线是在同一条长链上发出连续的请求。想象很美好,现实很残酷,流水线受制于很多问题。
一个post请求的java程序
#
@Test
public void test3() throws IOException {
URL url = new URL("http://xiaoxiang.space/login/");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//用户可以输出到该URLConnection
connection.setDoOutput(true);
String param = "password=" + URLEncoder.encode("小象", "UTF-8");
//request headers
connection.setRequestMethod("POST");
connection.setRequestProperty("Accept", "text/html");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0");
connection.setRequestProperty("Content-Type", "application/x-www-form-urlencoded; charset=UTF-8");
//general headers
connection.setRequestProperty("Connection", "close");
//entity headers,必须放在request headers和general headers后面,否则会报错
connection.getOutputStream().write(param.getBytes(StandardCharsets.UTF_8));
//关闭重定向,可以打开试一试
connection.setInstanceFollowRedirects(false);
connection.connect();
System.out.println("\n响应头:");
connection.getHeaderFields().forEach((k, v) -> {
System.out.println(k + ": " + v);
});
//如果有网页的话会输出该网页
InputStream inputStream = connection.getInputStream();
Scanner scanner = new Scanner(inputStream,"utf-8");
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
}
2021-02-19
- MIME:multipurpose internet mail extensions媒体类型
- 浏览器通常使用mime类型来确定如何处理url
语法
#
通用结构
#
类型
#
#text表明是普通文本
text/html
text/css
text/xml
#image表示是某种图像(包括动态图片)
image/jpeg
image/png
#applicaiton表示是某种二进制数据
application/pdf
application/json
text/javascript
#audio表示是某种音频文件
#video表示是某种视频文件
#multipart表示细分领域的文件类型的种类
#...
部分MIME类型介绍
#
application/octet-stream:这是应用程序的默认值,意思是未知的应用程序文件。text/plain文本的默认值text/css:网页中要被解析为css的任何css文件必须指定MIME为text/css。
参考链接:
MIME类型 |
常见MIME类型列表
2021-02-08
linux指令执行过程
#
- linux在下达一个指令时,会按照以下的顺序寻找(所以当直接在bash中输入xxx.sh时是不会执行的):
- 以相对/绝对路径执行指令如/bin/ls,或./ls。
alias lm='ls -al':给命令设定别名;alias:可以查看系统的所有别名;使用unalias lm取消别名。- 由bash内建的指令来执行。
- 通过$PATH这个变量的顺序搜寻到第一个指令来执行。
- 使用
which指令可定位到程序的位置。
linux进程
#
-
进程(process):程序被触发后,执行者的权限与属性、程序及程序所需的数据都会被加载到内存中,操作系统给与这个内存内的单元一个标识符PID。
-
当登入系统后,会取得一个bash,当使用这个bash提供的接口去执行另一个指令时,另外执行的指令也会生成PID,这个新进程就是子进程,而原来的bash环境就是父进程。linux中进程通常由父进程以复制(fork)的方式产生一个一摸一样的子进程,然后被复制出来的子进程再以exec的方式来执行实际要进行的程序,最终就会成为一个子进程。
- 系统先以fork的方式复制一个与父进程相同的暂存进程,这个进程与父进程唯一的差别就是PID不同,此外这个暂存进程还会多一个PPID(parient pid)的参数。
- 暂存进程开始以exec的方式加载实际要执行的程序。
-
常驻内存中的进程通常提供一些功能以服务用户,因此这些常驻程序就会被称为:服务(daemon)。
lspci 获取本机PCI相关信息
#
lspci -tv显示PCI树和树上设备的名称。lspci -vvvs bus:device.function 显示此设备的配置空间,-vvv也可以是-vv,信息会少一点。例:lspci -vvvs 2c:00.0。lspci -xxxxs bdf 以十六进制显示PCI设备的配置空间。lspci -vvv 获取所有设备的配置空间。
setpci 设置PCIe配置空间
#
setpci -s b:d.f reg.[B|W|L]=value 写PCIe配置空间reg寄存器的值,其中B表示一个字节,W表示两个字节,L表示四个字节。例:setpci -s 60:03.1 0x60.b=0x57
dmidecode 获取SMBIOS信息
#
ext4文件系统调试
#
- 获取文件的inode
ls -ila。
- 读取文件的inode信息
stat /etc/passwd(需要指定全路径)。
- 获取inode所在的block位置
debugfs /dev/sda1 -R "imap <6029951>" | tee。
- 将十六进制转为十进制并显示
echo $((0x4002))。
- 获取文件系统类型
df -Th。-T表示打印文件系统Type。通过df -i还能看到文件系统当前的inode总数和剩余inode数量。
- 根据inode号获取inode信息和data block的位置
debugfs /dev/sda1 -R "stat <6029951>" | tee,使用tee看起来更直观。
- 查看super block和group descriptors的信息
dump2fs /dev/sda1。
- 读取磁盘指定block位置的数据
dd if=/dev/sda1 bs=4096 count=1 skip=6327982,其中if表示输入文件,bs表示块大小,count表示几个快,skip表示跳过多少块。可以使用xxd来显示十六进制 dd if=/dev/sda1 bs=4096 count=1 skip=6327982 | xxd。
- 文件被删除后,在目录下是看不到该文件的,但是该文件的inode信息其实还存放在目录中,可以通过如下命令拿到文件的inode号
debugfs /dev/sdd3 -R "ls -d /dir1"(注意,此路径不是挂载的全路径,而是直接从文件系统的根路径开始)。
- 删除文件只是将文件inode中的block数组给置零了,文件内容其实没有删除。
- 例(查看inode的extent信息):
- 使用
ls -li获取inode number。
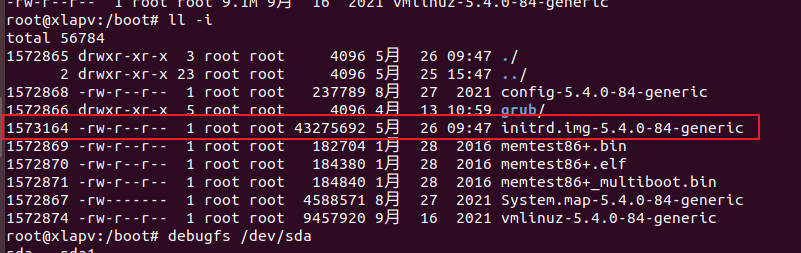
- 查看此inode的信息。
debugfs /dev/sda1 -R "stat <1573164>"
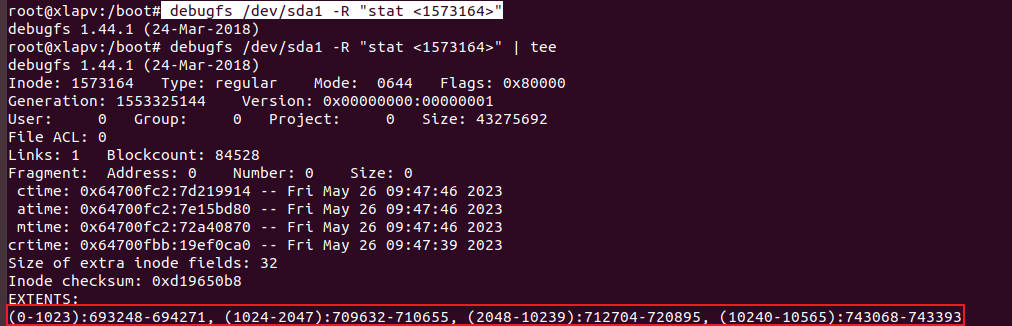
- 或取此inode所在的块。
debugfs /dev/sda1 -R "imap <1573164>" | tee

- 根据块号和偏移量找到相应的inode的数据。
dd if=/dev/sda1 count=1 bs=4096 skip=6291506 |xxd

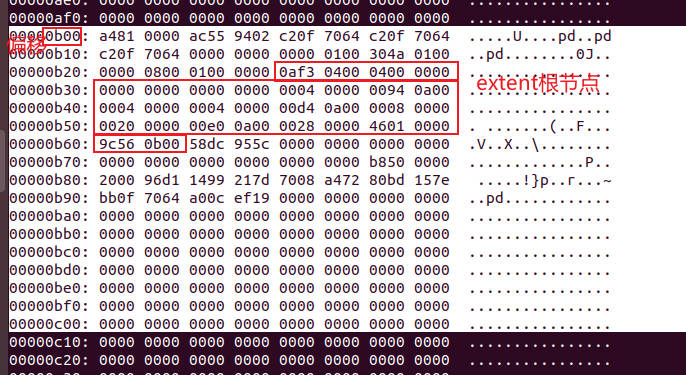
- 解析后的结果如下:
//0af3 0400 0400 0000 0000 0000
ext4_extent_header
{
eh_magic = 0xF30A //magic number 2byte
eh_entries = 4 //header之后的entry数量 2byte
eh_max = 4 //header之后最大的entry数量 2byte
eh_depth = 0 //树的深度 2byte
eh_generation = 0
}
//第一个extent 0000 0000 0004 0000 0094 0a00
struct ext4_extent
{
ee_block = 0 //当前是第几个块(这里的块和文件系统的块不同) 4byte
ee_len = 1024 //多少个块 2byte
ee_start_hi = 0 //块号高16位 2byte
ee_start_lo = 693248 //块号低16位 4byte
}
//第二个extent 0004 0000 0004 0000 00d4 0a00
struct ext4_extent
{
ee_block = 1024 //当前是第几个块(这里的块和文件系统的块不同) 4byte
ee_len = 1024 //多少个块 2byte
ee_start_hi = 0 //块号高16位 2byte
ee_start_lo = 709632 //块号低16位 4byte
}
//第三个extent 0008 0000 0020 0000 00e0 0a00
struct ext4_extent
{
ee_block = 2048 //当前是第几个块(这里的块和文件系统的块不同) 4byte
ee_len = 8192 //多少个块 2byte
ee_start_hi = 0 //块号高16位 2byte
ee_start_lo = 712704 //块号低16位 4byte
}
vim 文本编辑工具
#
通过配置~/.vimrc(不建议修改/etc/vimrc)可以设定一些vim的属性,在vim的命令模式输入:set all可以查到
ctrl+f向下移动一页ctrl+b向上移动一页0或者home移动到这一列的最前面$或end移到这一列最后一页G(注意是大写)移到文件的最后一列gg移到文件的第一行n+enter光标向下移动n行/word搜索为名称为word的字符串:1,2s/word1/word2/g[第一行,第二行]中所有的word1被替换成word2:1,$s/word1/word2/g第一行到最后一行所有word1被替换为word2:1,$s/word1/word2/gc第一行到最后一行所有word1被替换为word2,且在取代前会提示字符给用户确认dd删除当前一整行,ndd 删除光标所在的向下n行yy复制一整行,4yy 复制4行。p将复制的数据在光标的下一行粘贴,P在光标的上一行粘贴u复原前一个动作ctr+r重复上一个动作:w [filename]将文件另存为:set nu/nonu开启/关闭行号:set ic 忽视大小写
nmcli 网络配置工具
#
-
目前主流网卡为使用以太网络协议开发出来的以太网卡(Ethernet),所以linux称呼这种网络接口为ethN(N为数字)。新的centos7对网卡的编号有另一套规则,网卡待会现在与网卡的来源有关:eno1(BIOS内建的网卡),ens1(BIOS内建的PCI-E网卡),enp2s0(PCI-E)界面的独立网卡。
-
nmcli可用来设置ip、dns等配置,与直接修改/etc/sysconfig/network-scripts/ifcfg-xxx(centos7)、/etc/NetworkManager/system-connections/ethernet-xxx(ubuntu18)等效。
-
一个网卡设备可以有多个配置,但是只能有一个为激活状态,多个配置可以在不同的网络环境中切换。比如小明在公司用静态IP的方式连接到网络,在家用DHCP的方式连接网络,可以创建两个connections,一个叫static-conn,另一个叫dhcp-conn,当需要使用DHCP的方式时,执行nmcli con up dhcp-conn激活配置,当使用静态IP的方式时,执行nmcli con static-conn激活配置。
nmcli connection {show | up |down| modify | add | edit |clone | delete |monitor | reload | load | import | export } ARGUMENTS...
#为网卡enp0s8创建一个配置
nmcli connection add ifname enp0s8 type ethernet ipv4.method auto
#在一个交互式的窗口中为ethernet-enp0s8编写配置
nmcli connection edit ethernet-enp0s8
#修改ethernet-enp0s8的网络参数
nmcli connection modify enp0s8 \
connection.autoconnect yes \ #是否开机就启动这个配置
ipv4.method manual \ #自动(DHCP)还是手动设定网络参数
ipv4.addresses 192.168.x.x/24 \ #设定地址
ipv4.gateway 192.168.x.x \ #设定网关
ipv4.dns 192.168.x.x #设定DNS
ipv4.never-default yes #设定不为默认路由
#移除某个配置,只需要将该配置的值置为空
nmcli con modify ethernet-enp0s8 ipv4.dns ""
#为ethernet-enp0s8添加dns的配置(因为dns和ip能有多个配置,所以可以用+和-,不能有多个配置的不能用)
nmcli con modify ethernet-enp0s8 +ipv4.dns 8.8.8.8
#为ethernet-enp0s8删除ip的配置
nmcli con modify ethernet-enp0s8 -ipv4.addresses "192.168.100.25/24"
#修改配置名称
nmcli connection modify ethernet-enp0s8 con-name
#列出所有的配置。
nmcli connection show
#仅列出激活状态的配置。
nmcli connection show --active
#列出ethernet-enp0s8的配置。
nmcli connection show ethernet-enp0s8
#激活enp0s8设备的配置。
nmcli connection up ifname enp0s8
#激活名称为ethernet-enp0s8的配置。
nmcli connection up ethernet-enp0s8
#删除ethernet-enp0s8的配置
nmcli connection delete ethernet-enp0s8
#导入一个openvpn的配置给networkmanager
nmcli con import type openvpn file ~/Downloads/frootvpn.ovpn
#增加一个ip地址(多ip地址)
nmcli c modify mark +ipv4.addresses 10.2.0.31/24
#去掉一个ip地址
nmcli c modify mark +ipv4.addresses 10.2.0.31/24
/etc/network/interfaces网络配置
#
- 修改/etc/network/interfaces配置文件
#指定 enp0s3 接口在启动时自动激活。
auto enp0s3
#指定 enp0s3 接口的配置方式为静态 IP 地址。
iface enp0s3 inet static
address 192.168.1.110
netmask 255.255.255.0
gateway 192.168.1.1
/etc/sysconfig/network-scripts/ifcfg-xxx配置介绍
#
#最小配置
DEVICE=eth1 #网卡号,必须与文件名对应
ONBOOT=yes #是否默认启动,要联网必须要配置
BOOTPROTO=none #是否使用dhcp,是的话BOOTPROTO=dhcp
HWADDR=08:00:27:35:2F:f2 #mac地址
IPADDR=172.27.32.6 #ip地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=172.27.32.1 #网关
firewall-cmd centos7下的防火墙工具
#
#查看防火墙的状态
systemctl status firewalld
#关闭防火墙并禁止开机自启
systemctl stop firewalld; systemctl disable firewalld
#启用防火墙并允许开机自启
systemctl start firewalld; systemctl enable firewalld
-
防火墙的服务名为firewalld,centos7使用firewall-cmd来管理防火墙。
-
firewalld预先准备了几套防火墙策略集合(zone)。常见的zone:1. trusted允许所有的数据包;2. home;3. internal;4. work;5. public;6. external;7.dmz;8. block;9.drop。
-
常见命令:
- –get-default-zone查询默认的zone;- -set-default-zone设置默认的zone,–get-zones显示可用的zone;
- –list-all显示当前区域的网卡配置参数、资源、端口及服务等信息; –list-all-zones显示所有区域的网卡配置参数、资源、端口及服务等信息;
- –add-service=服务名、–remove-service=服务名;
- –add-port=端口号/协议、–remove-port=端口号/协议;–list-ports列出已开放的端口。
- –add-forward-port=port=源端口号:proto=协议:toport=目标端口号:toaddr:目标ip地址。
- –panic-on/–panic-off启动/关闭应急状态,阻断一切网络连接。
-
firewalld设置只在下次重启前有效,如果需要永久生效,需要加上–permanent模式,并执行firewall-cmd –reload。
#永久放开3306端口,并立刻生效
firewall-cmd --add-port 3306/tcp --permanent
firewall-cmd --reload
#永久拒绝192.168.10.0/24网段的所有用户访问本机的ssh服务。
firewall-cmd --permanent --zone=public --add-rich-rule="rule family="ipv4" source address="192.168.10.0/24" service name="ssh" reject"
nmap
#
nmap [扫描类型] [扫描参数] [主机地址]
扫描类型:
-sS:扫描TCP,通过SYNACK报文判断
-sP:以ping的方式扫描
-sT:扫描TCP,通过建立tcp连接
-sU:扫描UDP
扫描参数:
-p 扫描端口,如80,80-1023等
主机地址:
如192.128.0.0/24,192.168.1.100,192.168.1.1-50,60-100
nmap -sS 10.2.4.2
iptables
#
-
参考链接:
Iptables Tutorial 1.2.2 (frozentux.net)
-
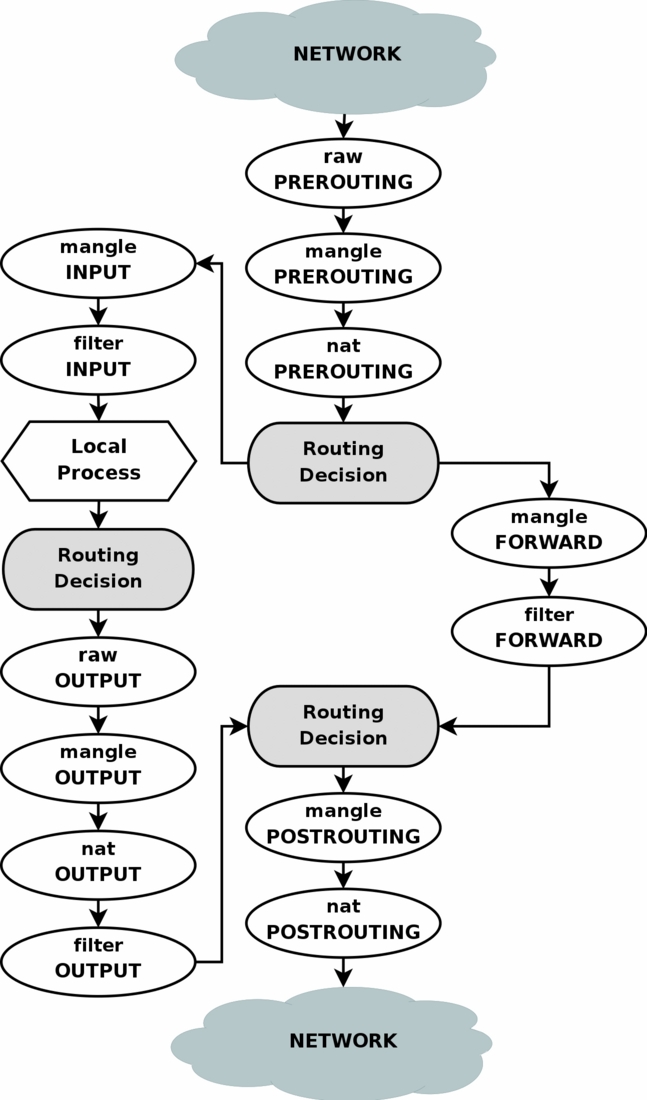
REDIRECT用于将数据包转发到本机,数据包目的地址将映射到127.0.0.1地址,只能用于nat表的PREROUTING和OUTPUT。
-
iptables有4张表,每个表和其中的链用途如下:
- filter(过滤器):主要跟进入Linux本机的数据包有关
- INPUT:进入Linux的数据包
- OUTPUT:Linux发出去的数据包
- FORWARD:和Linux本机无关,他可以转发封包到后面的计算机
- nat(地址转换):主要是进行IP或端口的转换:
- PREROUTING:在进行路由判断之前要进行的规则(DNAT/REDIRECT)
- POSTROUTING:在进行路由判断之后要进行的规则(SNAT/MASQUERADE)
- OUTPUT:与发出去的数据包有关
- mangle(破坏者)
- raw
-
查看防火墙规则
iptables [-t tables] [-L] [-nv]
-t 后面跟表名,默认为filter
-L 列出目前table的规则
-n 不获取HOSTNAME,速度快
-v 显示更多信息
--line-numbers 显示行号
结果介绍:
Chain那一行的括号里的policy就是预设的策略。
---
target:表示进行的动作,ACCEPT是放行,REJECT是拒绝,DROP是丢弃。
prot:表示协议,如tcp、udp、icmp。
in:表示输入网口
out:表述输出网口
source:表示此规则是针对哪个来源做处理
destination:表示此规则是针对哪个目标进行限制
说明栏:
iptables [-t nat] -P [INPUT, OUTPUT, FORWARD] [ACCEPT, DROP]
相关命令
#
#拒绝来自10.2.4.2 tcp20000端口的数据包,使用REJECT会返回一个port-unreachable的ICMP
iptables -A INPUT -s 10.2.4.2 -p tcp --dport 20000 -j REJECT
#拒绝来自10.2.4.5的数据,将此规则插入到链第二个节点
iptables -t filter -I INPUT 2 -s 10.2.4.5 -j REJECT
#(10.2.4.56主机)将5140 udp端口的数据复制一份到10.2.4.31上
iptables -t mangle -A PREROUTING -p udp --dport 5140 -j TEE --gateway 10.2.4.31
#(10.2.4.31主机)将目标IP地址为10.2.4.56、udp端口为5140的数据转发到本地的5141端口
iptables -t nat -A PREROUTING -d 10.2.4.56 -p udp --dport 5140 -j REDIRECT --to-ports 5141
#删除nat表PREROUTING链的第二条规则
iptables -t nat -D PREROUTING 2
systemctl 管理unit
#
- 一般linux上的服务会在服务名后面加上一个d,这个d就表示daemon。
- systemd将daemon执行脚本称为的一个unit。一般情况下安装的应用的unit都会放到
/usr/lib/systemd/system/下;而在/etc/systemd/system/目录下会存放unit的一些配置。
- unit有多种类型,包括 ①service:服务类型;②socket;③target:执行环境类型,是一群unit的集合;④mount、automount:文件系统挂载相关的服务;⑤path:侦测特定的文件或目录类型;⑥timer:循环执行的服务。常用的即使service和target,比如mysqld.service(mysql服务),firewalld.service(防火墙)。
- 通过systemctl可以管理unit,格式如下:
systemctl [command] [unit],其中command如下:
- start:启动。例
systemctl start mysqld.service。
- stop:停止。
- enable:开机启动。例
systemctl enable mysqld.service。
- disable:禁止开机启动。
- status:unit的状态。
- is-active:是否运行。
- 执行
systemctl status xxx,会显示该unit的状态。结果的第二行表示该服务是否会开机启动,结果的第三行表示该服务的当前状态。
- 一个daemon的预设状态有多个,包括:
- enabled:这个daemon会在开机被执行。
- disabled:这个daemon在开机不会被执行。
- static:这个daemon不可以自己启动(即不能使用
systemctl enable xxx来设置开机自启),但可以被其他的服务来唤醒。
- mask:注销状态,这个daemon无法被启动,可以通过
systemctl unmask xxx改会原来的状态。
systemctl [list-units]列出目前启动的unit;systemctl list-units --all列出所有的unit。systemctl list-unit-files列出所有已安装的unit。
unit文件说明
#
Unit
#
- Description: 当前unit的描述
- Documentation:文档地址,可接受 “
http://”,"https://","file:","info:", “man:” 五种URI类型。
- Requires:表示本unit和其他unit之间有强依赖关系。
- Wants:是
Requires= 的弱化版。当此单元被启动时,所有这里列出的其他单元只是尽可能被启动。但是,即使某些单元不存在或者未能启动成功,也不会影响此单元的启动。推荐使用此选项来设置单元之间的依赖关系。
- Before、After:强制指定unit的启动顺序,不涉及依赖关系。
- OnFailure:接受一个空格分隔的单元列表,当单元启动失败时,将会启动列表中的单元。
- 相关链接:
systemd.unit 中文手册
service类型的unit特有的的Service
#
-
Type
- simple:如果设为
simple ,那么 ExecStart= 进程就是该服务的主进程,systemd 会认为在创建了该服务的主服务进程之后,该服务就已经启动完成。如果execStart指定的可执行文件不存在或User=的用户不存在,systemctl start也仍然会执行成功。除了simple之外的类型都需要等待服务完成初始化,所以可能减慢系统启动速度。
- exec:和simple类似,但该服务只有在主服务的进程执行完成后,systemd才会认为该服务启动完成。
simple 表示当 fork() 函数返回时,即算是启动完成,而exec 则表示仅在 fork() 与 execve() 函数都执行成功时,才算是启动完成。对于exec来说,如果不能成功调用主服务进程(如User不存在、后可执行文件不存在),则systemctl start会执行失败。
- forking:ExecStart=进程将会在启动过程中使用
fork() 系统调用。也就是当所有通信渠道都已建好、启动亦已成功之后,父进程将会退出,而子进程将作为主服务进程继续运行。在这种情况下,systemd 会认为在父进程退出之后,该服务就已经启动完成。如果使用了此种类型,那么建议同时设置 PIDFile= 选项,以帮助 systemd 准确可靠的定位该服务的主进程。systemd 将会在父进程退出之后立即开始启动后继单元。
- oneshot:只有当该服务的主服务进程退出后,systemd才会认为该服务启动完成。通常需要设置 RemainAfterExit=yes ,使、systemd 在服务进程退出之后仍然认为服务处于激活状态。
notify 与 exec 类似,不同之处在于,该服务将会在启动完成之后通过
sd_notify(3)之类的接口发送一个通知消息。idle 与 simple 类似,不同之处在于,服务进程将会被延迟到所有活动任务都完成之后再执行。这样可以避免控制台上的状态信息与shell脚本的输出混杂在一起。注意:(1)仅可用于改善控制台输出,切勿将其用于不同单元之间的排序工具;(2)延迟最多不超过5秒,超时后将无条件的启动服务进程。
-
ExecStart:启动服务时需要执行的命令+参数。
-
ExecReload:用于设置该服务被要求重新载入配置时需要执行的命令行。有一个特殊的环境变量$MAINPID用于表示主进程的PID,可以这样使用/bin/kill -HUP $MAINPID。
-
ExecStop:用于设置服务被要求停止时所执行的命令行。
-
Restart:当服务经常正常退出、异常退出、被杀死、超时的时候,是否重新穷该服务。可以为on、on-success、on-failure、on-abnormal、on-watchdog、on-abort、always之一。默认是no。always表示服务会被无条件的重启,on-success表示仅在服务进程正常退出时重启,正常退出是指:退出代码为0或进程收到 SIGHUP, SIGINT, SIGTERM, SIGPIPE 信号之一, 并且 退出码符合 SuccessExitStatus= 的设置。on-failure 表示 仅在服务进程异常退出时重启, 所谓"异常退出" 是指: 退出码不为"0", 或者 进程被强制杀死(包括 “core dump"以及收到 SIGHUP, SIGINT, SIGTERM, SIGPIPE 之外的其他信号)。
-
| 退出原因(↓) | Restart= (→) |
no |
always |
on-success |
on-failure |
on-abnormal |
on-abort |
on-watchdog |
| 正常退出 |
|
X |
X |
|
|
|
|
| 退出码不为"0” |
|
X |
|
X |
|
|
|
| 进程被强制杀死 |
|
X |
|
X |
X |
X |
|
| systemd 操作超时 |
|
X |
|
X |
X |
|
|
| 看门狗超时 |
|
X |
|
X |
X |
|
X |
-
RestartSrc:设置在(Restart)前暂停多长时间,默认值为100ms,如果未指定时间单位,默认单位是秒。
-
相关链接:
systemd.service 中文手册
service
#
- KillMode:设置单元停止时,杀死进程的方法:control-group、process、mixed、none。默认值是control-group。
install
#
- WantedBy:表示在使用systemctl enable启用此单元时,将会在每个列表单元的.wants下创建一个指向该单元的软链接,相当于为每个列表中的单元文件添加了Wants=此单元选项,这样当单元启动时,该单元就会被启动。注:
multi-user.target通常是包含在graphical.target中。
[root@localhost ~]# cat /usr/lib/systemd/system/nginx.service
[Unit]
Description=nginx
[Service]
Type=forking
PIDFile=/opt/nginx/logs/nginx.pid
ExecStart=/opt/nginx/sbin/nginx
ExecReload=/opt/nginx/sbin/nginx -s reload
Restart=on-failure
ExecStop=/opt/nginx/sbin/nginx -s quit
[Install]
WantedBy=multi-user.target
- systemd取消了以前的runlevel概念,转而使用不同的target操作环境。常见的操作环境为multi-user.target(命令行界面)和graphical.target(图形界面)。不重新启动而转不同的操作环境使用
systemctl isolate unit.target,设定预设的环境使用systemctl set-default multi-user.target。
RPM 软件管理机制
#
-
RPM全称:RedHat Package Manager
-
RPM是通过预先编译打包成RPM文件格式后,再加以安装的一种方式。RPM在打包软件的同时会加入一些其他的信息,包括软件版本、作者、依赖的其他软件等。RPM会在linux系统上建立一个RPM软件数据库,当要安装某个软件时,RPM会去在数据库里检测是否已经存在相关软件,如果不存在就不能安装。
-
当软件安装完毕后,该软件相关的信息就会被写入到/var/lib/rpm目录下的数据库文件中了。未来任何软件升级的需求,版本之间的比较都是来自于这个数据库。
-
rpm -ivh package_name安装软件
- -i install;-v查看安装信息界面;-h显示安装进度
- –force:强制安装,–test:测试一下该软件是否可以被安装到linux中
- –prefix 新路径:将软件安装到其他路径
-
rpm -Uvh/-Fvh file-1.0-1.e17.x86_64.rpm 更新软件
- -U:update后面的软件即使没有安装过,系统会直接安装,如果安装过旧版,系统会更新到新版。
- -F:freshen后面的软件如果没有安装就不安装,如果安装过旧版就更行到新版。
-
rpm -qa查询本机所有已安装软件
rpm -q package_name查询后面的软件是否被安装rpm -qi package_name列出该软件的详细信息rpm -ql package_name列出该软件所有文件与目录rpm -qR package_name列出该软件依赖那些软件rpm -qpR file-1.0-1.e17.x86_64.rpm查询某个rpm文件依赖了哪些文件,-p表示指定的是一个rpm文件。- tips:在查询本机上已安装的软件时,只用加上软件的名称即可,版本号啥的都不需要。
yum 包管理工具
#
当客户端有软件安装需求时,客户端会主动下载yum服务器中该软件的依赖清单,将该清单与本机的RPM数据库进行比较,就能安装未安装的依赖了。
yum提供了查找、安装、删除软件包的命令。
yum [options] [command] [package ...]
- options:可选,-y表示安装过程全部为yes,-q白哦是不显示安装过程,-h表示帮助,–installroot=路径:将软件安装到指定路径中。
- command:要进行的操作,如search、list、info。
- package:包名。
常用命令
#
yum check-update列出所有可更新的软件。yum update更新所有软件yum install package_name安装指定的软件yum update package_name更新指定的软件yum list 列出所有的可安装的软件
yum list packa*寻找以packa开头的软件
yum remove package_name删除软件yum search keyword_name查找软件包命令- yum会先下载软件库的清单到本机的
var/cache/yum中,清除缓存命令如下
yum clean packages/headers/all清楚缓存目录下的软件包/headers/所有软件库的数据。
netstat 显示网络状态
#
netstat -tulnp用来获取目前主机已启动的服务- -t/-u显示tcp/udp传输协议的连接情况
- -l显示监听状态的的服务
-a显示所有连线中的socket-n :显示数字而不是别名- -p显示socket的pid/程序名
tcpdump 抓包命令
#
-i interface监听指定的interface,如果未指定此参数,tcpdump会搜索系统interface上数字最小的interface(如eth0)监控。可以用-i any来监控所有的interface(此参数不会在promiscuous mode下工作)。-X显示原始16进制数据内容和ascii编码后的内容。-D 列出系统上可用的网络接口。-A 以ASCII的方式打印出每个包(不包括链路层头部)。-nn显示原始的ip地址和端口。-v产生详细的输出. 比如包的TTL,id标识,数据包长度,以及IP包的一些选项。-w 将抓到的数据包写入到文件中。-
tcpdump
- 例子
#以ASCII的形式显示在本机所有网卡、端口5140上监听的数据
tcpdump -A -i any -n port 5140
#监听端口不是5140
tcpdump -A -i any -n ! port 5140
#抓来源是10.0.1.81,目的端口是5140的数据
tcpdump -i any -nnA src host 10.0.1.81 and dst port 5140
#同时指定两个端口
tcpdump -i any -nnA port 8848 or port 5140
tcpdump -i any -nnA port 8848 or 5140
#指定端口范围
tcpdump -i any -nnA portrange 514-5140
#将抓到的数据保存到文件中
tcpdump icmp -w icmp.pcap
tcpdump icmp -r icmp.pcap
curl 强大的网络工具
#
-
(client url)通过指定的url上传或者下载数据。
-
curl xiaoxiang.space查看网页源码。
-
curl -o [文件名] xiaoxiang.space保存文件。
-
使用-L参数,当有重定向时,会跳转到新的网址。
-
-i显示http response的头信息,同时也会显示网页代码。
-
-I/--head只显示http response。
-
-v显示一次http通信的整个过程。
-
发送get请求和参数,直接把数据附加到网址后面就行。
-
curl -X POST --data-urlencode "data=xxx" example.com/xxx发送post请求。-X参数可以支持几个动词。
-
--User-Agent、--cookie等,--header增加一个头信息。
-
--user name:passwordhttp认证。
-
-k跳过ssl检测。
-
--limit-rate限制HTTP请求和回应的带宽。
-
参考链接:
curl网站开发指南 - 阮一峰的网络日志 (ruanyifeng.com)
-
参考链接:
curl 的用法指南 - 阮一峰的网络日志 (ruanyifeng.com)
ps 获取当前时刻系统进程状态
#
ps aux查询所有系统运行的进程
- %CPU:使用的cpu资源百分比;%mem:使用的内存资源百分比;vsz:使用的虚拟内存Kb;rss:占用的固定内存Kb;tty:该进程是在哪个终端机上运行,如果于与终端机无关则显示?;stat:进程目前状态(R运行;S睡眠但可被唤醒;D不可被唤醒;T停止状态;Z僵尸状态);time:实际使用cpu的时间。
--sort +rss 按照rss以递增[+]或者递减[-]的顺序排序 。
#按照cpu占用从大到小排序 并一页一页的显示
ps aux --sort -%cpu | more
- 使用
ps -lf显示当前的bash的进程。
- -l时较详细的输出当前bash的信息,-f是更完整的输出。🤣
- 输出中的S代表该进程的状态,主要的状态有:R running;S sleep;D 不可唤醒的睡眠状态,而可能是在等待I/O;T 停止状态;Z zombie僵尸状态。
- PRI/NI priority/nice 代表此进程被cpu所执行的优先级。PRI值越低代表优先级越高。优先级是由内核动态调整的,用户无法干涉,如果需要调整进程的优先执行次序时,可以通过修改Nice的值。一般来说有PRI(new)=PRI(old)+nice,但是最终的PRI也是有系统分析后决定的,nice的值有正有负,当nice为负数时,该进程就会降低pri值,所以会被较为优先的处理。nice的值的范围是
-10~19。一般使用者仅可以调整自己进程的nice值,范围为0~19,且只能将nice调高。使用nice和renice调整。
- nice:新执行的指令给予新的nice值
nice [-n 数字] command。
- renice:已存在进程的nice重新调整
renice [-number] PID。
- ADDR/SZ/WCHAN addr标识该进程在cpu的哪个部分,如果是running的进程,一般就会显示-,sz代表该进程用掉了多少的内存。wchaz代表进程目前是否在运行中。
- TIME代表使用掉的cpu的时间。
ps axjf可以列出来类似进程树的进程显示。pstree [-Apu] -p显示每个进程的pid,-u显示每个进程的所属账号。-A各个进程之间以ascii字符来连接。- 相关文档
The ps Command
top 动态显示进程状态
#
-
top [-d n]每隔n秒(默认为5)更新一次
- 第一行显示的是:当前时间、开机到现今经过的时间、登入系统的人数、系统在1、5、15分钟的平均工作负载
- 第二行显示进程总量、进程状态;第三行显示cpu整体负载;第四行和第五行显示物理内存和虚拟内存的使用情况。
- 第三行(%Cpus…)显示的是CPU的整体负载,wa表示I/O wait
- PR:priority,指进程的优先级、NI:Nice,于PR有关;TIME+表示CPU使用时间的累加
- 执行过程中按下M表示以内存的使用来排序,N表示已PID来排序,P表示以CPU来排序,T表示以TIME+来排序,按下q可以离开top
-p PID观察指定PID- 在top执行过程中可以按下**
P使得以CPU的使用资源排序,按下M以内存的使用资源排序,按下N**以PID来排序。按下c显示完整的路径和名称。
kill 向进程发送signal
#
kill -9 PID立刻强制删除一个工作kill [-15] PID以正常的方式结束一个工作- 例:当使用vim时,会产生一个.filename.swp文件,使用-15时,vim会以正常的步骤结束vi的工作,所以.filename.swp会被主动的移除,但如果使用-9,由于vim工作被强制移除了,所以.filename.swp就会继续存在文件系统中。
- 当想要进程执行某些动作时,可以给该进程一个工作号码,可以使用
kill -l 或者man 7 signal查到,主要的信号与名称对应关系。
| signal |
内容 |
| 1 SIGHUP |
启动被终止的进程,可以让该PID重新读取自己的配置文件,类似于重新启动 |
| 2 SIGINT |
相当于用键盘输入一个ctrl-c来中断一个进程的执行 |
| 9 SIGKILL |
强制中断一个进程的进行 |
| 15 SIGTERM |
以正常的结束进程来终止该进程 |
| 19 SIGSTOP |
相当于使用键盘ctrl-z来暂停一个进程的执行。 |
- kill可以帮我们将signal传递给某个%jobnumber(参考下面的job和fg命令)或者某个PID。
nohup和& 后台执行
#
- nohup会将标准输入重定向到/dev/null,将标准输出重定向到nohup.out(一般情况)或$HOME/nohup.out文件,将标准错误输出重定向到标准输出。
nohup COMMAND > FILE 保存输出内容到文件。nohup COMMAND & 后台执行命令。- 使用
&可以将任务丢到后台执行,但标准输出和标准错误输出仍然会被输出到屏幕上。
&将进程放到了背景执行,但是当退出bash后,进程就会被终止掉,如果需要退出bash后进程仍然能继续执行,可以使用nohup。nohup能在退出bash后还能继续执行工作。- 例:
nohup java -jar xxx.jar </dev/null 2>&1 & 将java命令放到后台执行,标准输出和标准错误输出都重定向到/dev/null
sed 正则工具
#
sed [-nefr] [n1[,n2]] function。
- -i 直接修改读取的文件;-n只有经过sed处理的行会被输出(配合q使用)。
- n1,n2表示选择进行操作的行数。
- function有:a 新增到的当前下几行;c 取代;d 删除;i 插入到当前的上一行;p 打印;s 取代,如1,20s/old/new/g。
#将显示到屏幕的内容删除第2-5行
nl /etc/passwd | sed '2,5d'
#删除第三行到最后一行
nl /etc/passwd | sed '3,$d'
#在第二行后面加上drink tea(就是加在了第三行)
nl /etc/passwd | sed '2a drink tea'
#在第二行后面加上了两行,每一行之间都要以反斜杠\来进行新行的增加
nl /etc/passwd | sed '2a drink tea \
drink beer'
#取代2-5行
nl /etc/passed | sed '2,5c No 2-5 number'
#仅列出/etc/passwd文件的第5-7行
nl /etc/passwd | sed -n '5,7p'
#删除5-7行
nl /etc/passwd | sed '5,7 d'
#去掉开始的空格,删除以1和2开始的行
nl /etc/passwd |sed 's/^ *//g' | sed '/^[1-2]/d'
#去掉有#注释的行和空白行
cat server.properties | sed '/^#/d' | sed '/^\s*$/d'
#将行末尾的.改为!
sed -i 's/\.$/\!/g' regular_express.txt
#文件的最后一行增加一行文字
sed -i '$a # This is a test' regular_express.txt
#删除文件中\r
sed -i 's/\r//g' file.txt
- 取代命令
sed 's/要被取代的字符串/新的字符串/g'
awk 数据处理工具
#
awk '条件类型1{动作1}' filename ,awk只能用单引号。- awk默认以空格或者[Tab]按键隔开,隔开的每一行的每个字段都是有变量名称的,那就是$1、$2…。$0表示一整行。
- NF表示每一行的字段总数;NR表示目前是第几行;FS表示目前的分割字符,默认是空格
- 参数-F可以指定分隔符,如
awk -F : '{print $(NF -1)}'
#输出账号和ip,有些数据格式不对
last -n 5 | awk '{print $1 "\t" $3}'
last -n 5| awk '{print $1 "\t lines: " NR "\t columns: " NF}'
#将分割字符设为冒号:,查询第三栏小于10,并只输出账号和第三栏
cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
#杀掉所有的java程序
jps |grep -vi jps | awk '{print $1}' | xargs -n 1 -I {} kill {}
job和fg 前台执行
#
- 可以使用
ctrl+z将任务丢到背景,状态是暂停。
- 使用
jobs -l可以观察当前背景中的任务。其中+代表最近被放到背景,-代表最近倒数第二个被放到背景。
- 使用fg可以将背景工作拿到前台来执行。命令:
fg &jobnumber。
- 删除背景中的工作。命令:
kill [-15 |-9] %jobnumber。
at与cron
#
at 只执行一次的任务
#
- 要使用at,需要先启动atd。我们使用at这个指令来产生要运行的工作,并将这个工作以文本文件的方式写入到/var/spool/at/目录内,该工作就能等待atd这个服务的取用与执行。
- at会先寻找/etc/at.allow这个文件,写在这个文件中的使用者可以使用at,不在这个文件中的用户不能使用at,即使用户没有写在at.deny中。如果不在这个文件中,at会寻找/etc/at.deny这个文件,写在这个文件中的使用者不能用at,不在这个文件中的使用者可以使用(也就是说两个文件存在一个就可以)。如果两个文件都不存在,就只有root可以执行at。
- at会将所有的标准输出和标准错误输出传送到执行者的mailbox中,解决方法是
echo "hello world" > /dev/tty1。
at [-ldv] TIME
-l 相当于atq,列出当前系统上面所有当前用户的未执行的at排程。
-d 相当于atrm,取消一个在at排程中的工作
-c 列出后面接的第几项项工作的实际指令内容at -c 2
TIME: HH:MM [YYYY--MM-DD] 18:02 2021-10-29
HH:MM [Month] [Date] 18:02 October 29
HH:MM[am|pm] + number [minutes|hours|days|weeks]
#再过5分钟后执行,ctrl+d退出
at now + 5 minutes
#查询还没执行的任务
atq
#删除3这个任务
atrm 3
cron 定时任务
#
- 与at类似,cron也有两个限制文件,/etc/cron.allow和/etc/cron.deny,/etc/cron.allow比deny要优先,两个文件只选择一个来限制,所以保留一个即可。系统默认保留/etc/cron.deny。
- 当用户使用crontab指令来建立工作排程后,该项工作就会被记录到/var/spool/cron里面去,而且以账号来判别。cron执行的 每一项工作都会被记录到/var/log/cron这个文件中。
- 下达指令最好使用绝对路径;cron会每分钟去读取一次/etc/crontab与/var/spool/cron里面的数据,所以编辑完文件后,cron会按照设定自动执行。
- 放到
/etc/cron.hourly目录内的所有执行文件(必须是shell脚本)会在每小时的一分钟开始后的5分钟内随机选择一个时间点来执行(详细请看/etc/cron.d/路径下的文件)。放到/etc/cron.daily、/etc/cron.weekly、/etc/cron.monthly下面的文件是由anacron执行的。而anacron执行方式是在/etc/cron.hourly/0anacron里面。
- crond预设有三个地方会有执行脚本配置文件,分别是
/etc/crontab ,/etc/cron.d/*,/var/spool/cron/*。
- 当执行项目有输出时,该数据会mail给MAILTO设定的账号,所以如果不是很重要,将输出重定向到/dev/null中。
- 建议个人的话使用
crontab -e来创建定时任务,系统维护人员直接使用vim /etc/crontab,开发的软件使用vim /etc/cron.d/newfile。
crontab [-u username] [-l | -e |-r]
-u 只有root可以使用这个参数。
-e 编辑crontab的工作内容
-l 查阅crontab的工作内容
-r 移除所有的crontab的工作内容,如果只移除一项,可以用-e编辑。
- 每项工作的格式都是具有六个字段,这六个字段的意义为:
| 分钟 |
小时 |
日期 |
月份 |
周 |
指令 |
| 0-59 |
0-23 |
1-31 |
1-12 |
0-7(0和7都表示星期天) |
指令 |
| 特殊符号 |
意义 |
| * |
代表任何时刻 |
| , |
代表该字段有多个参数,如每天3点和6点执行命令,为0 3,6 * * * command |
| - |
表示一段时间范围内,如8点到12点之间每小时的20分都进行一项工作,20 8-12 * * * command |
| /n |
n代表数字,表示每隔n单位的时间执行一此,如每隔5分钟执行一次,*/5 * * * * command,也可以写成0-59/5 * * * * command |
#使用哪种shell接口
SHELL=/bin/bash
#执行文件搜寻路径
PATH=/sbin:/bin:/usr/sbin:/usr/bin
#有输出时发给谁
MAILTO=root
#该文件中需要指定用户
1 * * * * * username command
anacron
#
-
/etc/cron.daily各字段含义:
- 天数:anacron 执行当下与时间戳 (/var/spool/anacron/ 内的时间纪录文件) 相差的天数,若超过此天数,就准备开始执行,若没有超过此天数,则不予执行后续的指令。
- 延迟时间:超过天数导致要执行定时任务,延迟执行的时间。
- 工作名称定义:通常与后续的目录资源名称相同即可。
- 实际要进行的指令串。
-
anacron执行流程(cron.daily):
- 由 /etc/anacrontab 分析到 cron.daily 这项工作名称的天数为 1 天;
- 由 /var/spool/anacron/cron.daily 取出最近一次执行 anacron 的时间戳;
- 由上个步骤与目前的时间比较,若差异天数为 1 天以上 (含 1 天),就准备进行指令;
- 若准备进行指令,根据 /etc/anacrontab 的设定,将延迟 5 分钟 + 随机n分钟 (看RANDOM_DELAY 的 设定);
- 延迟时间过后,开始执行后续指令,亦即『 run-parts /etc/cron.daily 』这串指令;
- 执行完毕后, anacron 程序结束。
free、uname、hostname、locale查看和设置系统信息
#
-
free -h查看内存使用情况。
-
uname [-asrmpi] -a表示所有;-s 系统核心名称;-r 核心的版本;-m 本系统的硬件名称(x86_64);-p CPU的类型;-i 硬件的平台。
-
uptime显示系统启动时间和工作负载。
-
hostnamectl [set-hostname 主机名] 修改主机名。
-
timedatectl [list-timezones | set-timezone | set-time | set-ntp] 列出系统上的失去、设定时区、设定时间、设定网络校时。
-
localectl set-locale LANG=en_US.utf8设置语系。通过locale -a可以查看linux支持了多少语系,通过locale来查看系统目前的语言环境。LC_ALL、LC_CTYPE、LANG这三个环境变量的值决定了操作系统当前使用的是哪种字符集,优先级是LC_ALL>LC_CTYPE>LANG。
-
硬件数据收集:dmidecode(CPU型号、主板型号、内存相关型号等), gdisk, dmesg, vmstat(分析cpu、内存、io目前的状态), lspci, lsusb,iostat。
ls 列出文件
#
cat、tac、tail、wc 查看文件
#
- cat:从第一行开始显示文件内容
- tac:从最后一行开始显示
- nl:显示的时候输出行号
- more:一页一页的显示文件内容
- less:与more类似,但是可以往前翻
/srting,向下搜索string?string,向上搜索string
- head:只看头几行
- 默认是显示10行
head -n -100 filename文件后面100行不显示
- tail:只看尾几行
- 默认是显示10行
tail -f filename文件内容如果有增加,输出增加的内容-n num filename输出文件末尾的n行,默认是10行tail -n +100 filename文件第100行(包括)以后都会被列出来
- od:以二进制查看
- file:查看文件类型
- wc:查看文件里有多少字,多少行,多少字符。
- wc [-lwm] -l表示列出多少行,-w表示列多多少字,-m表示列出多少字符。
重定向与管道
#
- 标准输入
<<或<;标准输出>>或>;标准错误输出2>或2>>。
>会覆盖原文件,>>会追加到文件中。如find /home -name .bashrc > list_right 2> list_error,将正确输出和错误输出存入到不同的文件中。- 黑洞装置
/dev/null,可以吃掉任何导向这个装置的信息。
- 将正确和错误输出都放到同一个文件中
find /home -name .bashrc > list 2>&1。对2>&1的理解,这里2表示错误输出,意思是将错误输出重定向到标准输出,&1表示对标准输出的应用。
- 管道
|只会处理标准输出,会忽略标准错误输出。
- 管道命令必须要接收上一个指令的标准输入,如less、more、head、tail时管道命令,而如ls、cp、mv就不是管道命令。
- 管道后面第一个必须是指令。
- 在管道中常常会使用前一个指令的输出作为后一个指令的输入,某些指令需要指定文件名来处理,该stdin和stdout可以使用
减号"-"来替代。如tar -cvf - /home | tar -xvf - -C /tmp/homeback,这个命令是将/home里的文件打包,将打包的文件输出到stdout,后面的命令从stdin读取数据,所以我们就不需要文件名了,直接使用-代替。
xargs [OPTION] COMMAND [R]:读入stdin的数据,并以空格符作为分割,将stdin分割成参数。
xargs -n 1表示每次执行指令值取一个参数。xargs -I R将从标准输入获取到的数据替换后面命令的参数R。xargs -i相当于xargs -I {}。(man手册里面不建议再使用-i了)- xargs的-I {}必须要放到-n前面。
- 例:
ls *.jar | xargs -I {} -n 1 sh start.sh {}
grep 查找指定内容
#
whereis、which、locale 查找文件
#
find:查找工具
#
tar 压缩与解压工具
#
tar -xzvf xxx.tar.gz解压文件
- -x extract提取文件;-z通过gzip处理文件;-v:verbose显示执行过程;-f指定文件名
tar -cvzf 生成的文件名.tar.gz dir/压缩文件
- -c:create生成文件
- tips:-C(大写)将文件放到指定文件夹
tar
- -c建立打包文件;-v查看执行过程;-x解压缩;-t查看打包文件内的情况;-C在特定目录解压缩;-z使用gzip解压缩;-j使用bzip2解压缩;-J使用xz解压缩;-f后面要立刻接上要被处理的文件名;-p保留备份数据原本权限与属性;–exclude=FILE压缩过程中不打包FILE。
gzip -[cdv#]:-c将压缩的数据输出到屏幕;-d解压缩;-v显示出原文件/压缩文件的压缩比等信息;-#表示数字,-1最快但压缩比最差,-9最慢但压缩比最慢,-6是默认。使用gzip压缩时,原文件会被压缩为***.gz,原文件就不存在了。bzip2 -[cdkzv#]:-c将压缩的数据输出到屏幕上;-d解压缩;-k保留源文件;-z压缩(默认,可不加);-v显示压缩比等信息;-#与gzip一样。文件名是xxx.bz2。xz [-dtlkc#]:-d解压缩;-t测试压缩文件完整性;-l列出压缩文件相关信息;-k保留原文件不删除;-c数据输出到屏幕上;-#和bzip2一样。-T0指定线程数量和CPU的数量一样。
useradd、passed、usermod、userdel 用户账号管理
#
- 默认情况下所有的系统上的账号和一般身份使用者,都记录在/etc/passwd这个文件中,个人密码记录在/etc/shadow文件下,所有组名都记录在/etc/group中。
- 当输入账号密码登陆后,系统先1. 寻找/etc/passwd里面是否有输入的账号,有的话读取UID和GID以及该账号的home目录和shell;2. 进入/etc/shadow找出对应的账号与UID,然后和对密码是否相符;3. shell启动。
- 查看已登录系统上的用户,可以使用
who。
/etc/passwd
#
- 每一行都代表一个账号,有几行就代表有几个账号在系统中。里面有很多账号本来就是系统正常运行所必需的,可以称之为系统账号。
#①账号名称:②x:③UID:④GID:⑤用户信息说明:⑥home目录:⑦shell
root:x:0:0:root:/root:/bin/bash
#账户名称需要和UID对应,UID就是使用者标识符,UID中0表示系统管理员;1~999表示系统账号(1~200表示系统自行建立的系统账号);1000~60000就是给一般使用者使用的。一个UID可以包含多个用户
#早期unix密码放在此文件中,后来放到了/etc/shadow中,这里用x替代。
#GID与/etc/group有关。
#当用户登陆系统后就会取得一个shell来与核心沟通。
/etc/shadow
#
#账号名称:密码:最近密码变动的日期:密码不可被更改的天数:密码需要修改的天数:密码需要变更前的警告天数:密码过期后多少天内还有效:账号失效日期:保留字段
#第四个字段的0表示随时都可以修改密码
root:$6$xtr:18894:0:99999:7:::
/etc/group
#
#组名:x:GID:此群组支持的账号名称
#每个用户都可以有多个群组
root:x:0:dmtsai,alex
- 在/etc/passwd中有个GID,即初始群组,初始群组不会加在/etc/group的第四个字段。
- 使用
groups命令可以获取当前账号所有的群组,输出的第一个群组为有效群组,新创建的一个文件使用的就是有效群组。通过newgrp xxx来切换有效群组。
- 相关命令:
groupadd groupmod groupdel
useradd
#
-g 初始群组 该字段会被添加到/etc/passwd第四个字段。-u UID -G 次要群组 -c 说明信息(/etc/passwd第五个字段) -r 系统账号 -s /bin/bash(指定一个初始的shell)。- -M 不建立home目录(系统账号默认) ;-m 建立home目录(一般账号默认)。
- useradd参考的是/etc/default/useradd文件,默认值可以通过
useradd -D查看;除此之外,还参考了/etc/login.defs文件。
- 相关命令:
id chsh
adduser --ingroup sudo h1c,ubuntu上可以使用此命令交互式创建用户,创建好的目录和命令完整。
passwd
#
- 使用useradd建立了账号后,默认情况下无法使用该账号登陆,需要使用passwd设定密码。
-l lock,会在/etc/shadow第二栏最前面加!使得密码失效,-u unlock,与-l相反;-S 列出秘密相关参数;-n 多久不可修改密码;-x 多久内必须修改密码; -w 密码过期前多少天开始警告 ;-i 密码失效日期;--stdin 从控制台获取输入。- 其他命令
chage -l user。
usermod
#
- 修改账号的数据。
- 添加群组
usermod -a -G wheel koal
userdel
#
- 删除用户的相关数据。
-r表示同时删除该用户的home目录。
chgrp、chown、chmod 文件权限
#
-
chgrp [-R] 文件/文件夹 改变文件的群组(必须是/etc/group中存在的)。
-
chown [-R] name:groupname 文件或目录来修改文件的拥有者,-R表示递归。
-
chmod [-R] 文件/目录 改变文件/目录的权限。
su 切换用户
#
su单纯使用su切换为root身份时,表明切换为root身份。读取变量的设定方式为non-login shell的方式,这种方式很多原本的变量不会改变。su - username使用该命令代表使用login-shell的变量文件来登入系统。su - -c 指令 执行一次root的指令。
sudo 以其他用户执行指令
#
ulimit 限制系统资源
#
ulimit 限制用户的某些系统资源(比如可以开启的文件数量)
ulimit -[SHacdfltu] [配置]
-H #hard limit,严格的限制,必定不能超过这个设定的数值
-S #soft limit,警告的设定,可以超过这个设定值,但超过则有警告。
-a #可列出所有的限制,-标识没有限制。
-f #此shell可以建立的最大文件大小,单位为KB。
-t #可使用的最大CPU时间,单位为秒。
-u #单一用户可以使用的最大程序的数量。
-d #程序可以使用的最大segment容量。
-l #可用于锁定(lock)的内存量。
#一般身份如果设置了ulimit的值,通过注销再登录即可恢复,也可以重新设定
#限制只能建立10MB以下容量的文件
ulimit -f 10240
#文件详细描述
vbird1 soft fsize 90000
#第一个字段为账号,或者为群组,如果是群组需要加上@。如果使用群组,这个功能只对初始群组有效。
#第二个字段为限制的模式,是严格hard还是警告soft。
#第三个字段为限制,比如是限制文件容量等。
#第四个字段为限制的值
#限制prol这个群组每次只能有1个用户登录
@prol hard maxlogins
#文件修改后需要重新登录才会有效。
ACL
#
- Access Control List,用来提供在owner、group,others的rwx之外的权限设定,可以针对单一使用者,单一文件或目录来进行rwx的权限规范。
#检查系统是否支持ACL
dmesg | grep -i acl
#设定acl参数
setfacl[-bkRd] [{-m | -x} acl参数] 目标文件名
-m : 设定acl参数给文件使用
-x : 删除后面的acl参数
-b : 移除所有的acl参数设定
-k : 移除预设的acl参数
-R : 递归设定acl
-d : 设定预设的acl参数,只对目录有效,在该目录新建的数据都会引用此默认值
#为xiaoxiang用户设定文件的权限为rwx
#一个文件设定了ACL参数后,他的权限部分就会多出来一个+号。
setfacl -m u:xiaoxiang:rwx file1
#为文件使用者设定权限
setfacl -m u::rwx file2
#为群组设置权限
setfacl -m g:mygroup:rx file3
#为目录设置acl权限,未来文件的acl权限都继承此目录
setfacl -m d:u:xiaoxiang:rx /home/xiaoxiang/dir1
#让xiaoxiang无法使用该目录
setfacl -m u:xiaoxiang:- /home/xiaoxiang/dir2
#取消某个账号的ACL权限设定
setfacl -x u:xiaoxiang /home/xiaoxiang/file5
#获取file1的acl权限内容
getfacl file1
#结果中#开头的表示默认值
#结果中的mask表示用来规范最大允许权限
df和du
#
df查看文件系统的的信息。
df -h查看所有文件系统的信息。df -T查看所有文件系统的类型。df -iT查看所有文件系统的类型和inode的数量。
du [-hskm] 文件或目录名称 统计磁盘的使用情况。
- -h 易读的方式显示。默认情况下会递归展示目录,但不会展示文件。
- -s (summarize)列出总量。
- -d (–max-depth=N):N表示深度,1表示输出子文件夹的大小,2表述输出子文件夹的子文件夹的大小。
- -a (–all) 不加该参数表示只统计文件夹,加该参数表示统计所有文件。
- -k和-m 以kB/mB显示。
lsblk 列出磁盘列表
#
-f列出磁盘内文件系统的名称。-d仅列出磁盘本身,不会列出分区。- 输出信息介绍
- NAME装置的文件名
- MAJ:MIN 主要:次要装置代码
- RM 是否为可卸载装置 removable device
- SIZE 容量
- RO 是否为只读装置
- TYPE 是磁盘disk、分区槽partition还是只读存储器rom
- MOUNTPOINT 挂载点
mount 磁盘挂载
#
-
mount [-alt]LABLE=''/UUID=''/装置文件名 挂载点/umount挂载与卸载
mount /dev/sda2 /d 将/dev/sda2挂载到/d。umount [-f] 挂载点或装置文件名 -f强制删除。- -n 不写入/etc/mtab。
- -o后面可以跟一些挂载时额外加上的参数;1. asyn,sync 此文件系统是否使用同步写入(sync)或异步(async)的内存机制。默认为async。2. atime,noatime 是否修订文件的读取时间。3. ro,rw 挂载文件系统为只读或可写。auto,noauto 允许此文件系统被以mount -a自动挂载(auto)。4. dev,nodev 是否允许此文件系统上可建立装置文件。5.suid,nosuid 是否允许此文件系统上有suid的文件格式。6. ecex,noexec 是否允许此文件系统上有可执行文件。7. user,nouser 是否允许此文件系统让任何使用者执行mount,一般mount只有root可以进行,但下达该命令后,一般user也能对其进行挂载。8. defaults 默认为rw,suid, dev,exec,auto,nouser,async。9. remount 重新挂载。
- -a 依照配置文件/etc/fstab的数据将所有未挂载的磁盘挂载。
- -t 要挂载的文件系统的类型。
-
开机挂载(修改/etc/fstab[filesystem table])
- 参数格式:装置/UUID/LABEL 挂载点 文件系统 文件系统参数 dump fsck
- 例:UUID=XXX(使用blkid查询) /d ntfs defaults 0 0
- /etc/fstab是开机时的配置文件,实际的filesystem的挂载记录到/etc/mtab和/proc/mounts这两个文件中。
-
sh -c "xxx" 将一个字符串作为完整的命令来执行。
-
history n用来查询过去执行的指令,n表示显示最近n个命令。bash会记录使用过的指令,默认记录1000个,指令存放位置在~/.bash_history中。该文件会记录上一次登录之前的指令,而这一次登录所执行的指令都存在内存中,当注销后,这些指令才会记录到.bash_history中。
-
使用write可以给linux上的其他用户发消息,通过who可以查看目前有谁在线。通过write koal给所有以koal登录的用户发消息。通过mesg n来关闭接收消息,但无法拒绝root的消息。通过mesg y来开启接收消息。使用wall可以对系统上所有的用户发送消息wall "hello world"。
man(manual)用户手册
#
- man中有几个常用的数字的含义:1 用户在shell环境中可以操作的指令或可执行文件;2. 系统调用,如
man 2 open;3. 函数库调用;4. 特殊文件,如man 4 tty;5 配置文件或者某些文件的格式;6. 游戏;7. 杂项;8 系统管理员可用的指令。例:man 8 sudo;9. 内核例程。
- man page一般包含:①NAME:简短的说明;②SYNOPSIS:简短的指令下达语法说明;③DESCRIPTION:较完整的说明;④OPTIONS;⑤COMMANDS:当这个程序执行的时候,可以在此程序中下达的指令。⑥FILES:关联的文件;⑦SEE ALSO:其他可以参考的信息;⑧EXAMPLE:一些可以参考的范例。
- 快捷键:空格键:向下翻一页 [Page Up]:向上翻一页 [Page Down]:向下翻一页 [Home]:去第一页 [End]:去最后一页 /string:向下搜索string ?string:向上搜索string n/N:n表示下一个搜索,N表示上一个搜索。
SELinux
#
- 全称是Security Enhanced Linux。SELinux是在进行进程、文件等细部权限设定依据的一个核心模块。SELinux提供了一些预设的策略(Policy),并在政策内提供了多个规则(rule)。
- 自主式访问控制(Discretionary Access Control,DAC)是根据进程的拥有者与文件资源的rwx权限来决定有无存取的能力。
- 委任式访问控制(Mandatory Access Control,MAC)可以根据特定的进程和特定的文件资源来进行权限的管控,即使是root,在使用不同的进程时,取得到的权限不一定是root,而要看当时进程的设定而定。控制的主体由使用者变成了进程。
- SELinux是通过MAC的方式来管控进程,控制的主体是进程,而目标是该进程能否读取的文件资源。
- 主体(Subject):即进程。
- 目标(Object):主体目标能否存取的目标资源,一般就是文件系统。
- 策略(Policy):由于进程和文件数量庞大,SELinux会依据某些服务来制定基本的存取安全性策略,这些策略中由详细的规则(rule)来指定不同的服务开放某些资源的存取与否。Linux里提供了三个主要的策略,分别是:
- targeted:针对网络服务限制多,针对本机限制少,是预设的策略。
- minimum:仅针对选择的进程来保护。
- mls:完整的SELinux限制,限制较为严格。
- 安全性本文(security context):主体能不能存取目标除了策略指定外,主体和目标的安全性本文必须一致才能够顺利存取,安全性本文类似于文件系统的rwx。
- 主体如果要存取目标,首先需要通过SELinux政策内的规则;其次与目标资源的安全性本文对比;最后再检查目标的rwx权限。
安全性文本
#
- 文件的安全性文本是放到文件的inode内的,可以使用
ls -Z去观察安全性文本。
- 安全性文本主要用冒号分为三个字段。
identify:role:type。
- 身份识别(Identify),常见的有:
- unconfined_u:不受限的用户,也就是说该文件来自于不受限的进程所产生的。
- system_u:系统用户,大部分就是系统自己产生的。
- 基本上如果是系统或软件本身所提供的文件,大多就是system_u这个身份名称,如果是用户透过bash自己建立的文件,大多数是不受限的unconfined_u,如果是网络服务所产生的文件,或者是系统服务运作过程中产生的文件,大部分的识别就会是system_u。
- 角色(Role)
- object_r:代表的是文件或目录等文件资源。
- system_r:代表的就是进程。
- 类型(Type),一个主体进程能不能读取到资源,与类型有关,类型在文件和进程中的定义不太相同。在文件资源上称为类型Type,在进程上称为领域domain。
SELinux三种模式的启动、关闭和观察
#
- SELinux目前共有三种模式,分别为:
- enforcing:强制模式,代表SELinux正确的开始限制domain/type了。
- permissive:宽容模式,表示不会实际限制domain和type,但会有警告信息。
- disable:关闭,代表SELinux并没有实际运作。
#获取当前的SELinux模式
getenforce
#查询当前的策略
sestatus
#修改策略,修改/etc/selinux/config的SELINUX=enforcing
#SELinux在enforcing和permissive之间切换无需重启
#切换到disable或者从disable切换到其他需要重启
setenforce [0|1] #0表示permissive,1表示Enforcing
2021-02-04
mysql起步
#
- 查询版本和当前时间
select version(),current_date;
- mysql执行结束后会显示返回了多少行和用了多长时间,受网络其他因素影响
- 当输入多行,打算不执行这句sql语句,输入
\c
- 自带的的mysql database描述了用户的访问权限。
- unix下数据库名是大小写相关的。建议在创建数据库的时候要么全大写,要么全小写,可以在刚安装的时候修改my.cnf文件。
- 相邻的带引号的多个字符串会拼接成一个字符串。下面这两个等价:
linux上mysql布局
#
mysql安装
#
systemctl start mysqld启动mysql。- mysql安装后,会自动创建超级用户
'root'@'localhost',其密码在/var/log/mysqld.log,使用grep 'temporary password' /var/log/mysqld.log来寻找密码。
- 修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'newPassword'。
- mysql8修改成简单的密码会报错(试了下mysql5.7也会报错,解决方法一样)。解决流程如下:
- mysql8增加了一组变量来控制密码的长度、强度等。通过
SHOW VARIABLES LIKE 'validate_password%'来查看。
- validate_password.length用来要求密码的最小长度,这个参数不得小于
validate_password.number_count+validate_password.special_char_count+2*validate_password.mixed_case_count)。
- validate_password.policy会影响validate_password的其他变量是否有效(除validate_password.check_user_name),它的值可以为0(LOW),1(MEDIUM),2(STRONG)。为0则只检查length这个变量。
- 更改策略:
set global validate_password.policy=0;set global validate_password.number=4;
- 参考链接:
MySQL :: MySQL 8.0 Reference Manual :: 6.4.3.2 Password Validation Options and Variables
mysql配置
#
- mysql配置文件被划分为多个组,每个组有一个组名,用[]括起来。
[mysqld]
default-storage-engine=InnoDB
validate_password=OFF
mysql账户管理
#
- mysql将账户存储在mysq数据库的user表中。
CREATE USER用于创建性的mysql用户;账户首次创建没有特权,需要使用GRANT分配特权。
#如果不指定主机,默认就是'%'(所有ip都能访问)
CREATE USER 'jeffrey'@'localhost' IDENTIFIED BY 'password';
#删除用户。
DROP USER 'jeffrey'@'localhost';
#重命名现有的账户,可以用来解决账号只能在本地访问的问题。
RENAME USER 'jeffrey'@'localhost' TO 'jeff'@'%'
ALTER USER修改账户的信息(如修改密码)。不推荐使用SET PASSWORD来修改密码。
#修改自己的密码,USER()会返回当前登录用户的用户名和主机名
ALTER USER USER() IDENTIFIED BY 'password';
#锁定账户
ALTER USER 'jeffrey'@'localhost' ACCOUNT LOCK;
ALTER USER 'jeffrey'@'localhost' ACCOUNT UNLOCK;
GRANT用来对账户进行授权,REVOKE用来撤销账户特权。
#授予除GRANT和PROXY外的所有特权
#还可以授予ALTER、CREATE、DELETE、DROP、SELECT、UPDATE、GRANT OPTION
GRANT ALL ON db1.* TO 'jeffrey'@'localhost';
REVOKE INSERT ON *.* FROM 'jeffrey'@'localhost';
REVOKE ALL [PRIVILEGES], GRANT OPTION FROM 'jeffrey'@'localhost';
mysql系统变量
#
- mysql有很多的系统变量,能够影响程序的行为,很多命令都能在运行过程中修改。
#获取某个变量的信息
show [global | session] variables like 'xxx'
#获取默认存储引擎
show variables like 'default_storage_engine'
#获取默认的最大连接数
show variables like 'max_connections';
通过命令行设置系统变量
#
mysqld --max_connections=10
通过配置文件设置系统变量
#
[server]
max_connections=10
运行过程中修改系统变量
#
- 许多系统变量分为全局范围(global)和会话范围(session)。
- 并不是所有的变量都有全局范围和会话范围,如max_connections只有全局范围。
- 服务器在启动时会给所有的全局变量一个默认值,当有连接的客户端时,服务器为每个连接的客户端维护一组会话变量,并以全局变量的值初始化。
#全局设置存储引擎
set global default_sotrage_engine=MyISAM
#本次会话期间设置存储引擎
set [session] default_storage_engine=MyISAM
#获取会话范围的变量内容
show SESSION VARIABLES LIKE 'default_sotrage_engine'
#不写修饰符默认是session范围,如果一个变量没有session范围则显示global范围的值
show VARIABLES LIKE 'max_connections'
状态变量
#
- 状态变量有关服务器的运行情况。
- 状态变量不能人为设置。
show [global | session] status like [like 'xxx']
#查看当前有多少客户端与服务器建立了连接。
show status like 'threads_connected'
补充
#
-
很多变量不可修改,如version。
-
大部分系统变量都可以当启动选项传入。
mysql字符集
#
常见字符集
#
- ASCII:共128个字符,用一个字节编码。
- ISO 8859-1:共收录256个字符,在ASCII的基础上扩充了128个西欧常用字符。这个字符集也有一个别名Latin 1。
- GB2312:收录了6763个汉字以及部分其他编码,兼容ASCII字符集,如果该字符集在ASCII字符集中,则采用一字节编码,否则采用两字节编码。
- GBK:在GB2312的基础上进行了扩充,兼容GB2312。
- UTF-8:几乎收录了当前世界上各个国家和地区使用的字符,而且还在不断扩充,采用变长编码的方式,编码一个字符需要1~4个字节。
mysql的字符集和比较规则
#
utf8和utf8mb4
#
- utf8mb3:阉割过的utf-8,只使用1~3个字节表示字符。mysql中的utf8就是utf8-mb3的别名。
- utf8mb4:正宗utf-8,使用1~4表示字符。
字符集查看
#
SHOW CHARSET [LIKE 'utf8%']
#结果中的maxlen表示此字符集最多需要几个字节表示一个字符。
比较规则
#
SHOW COLLATION [LIKE 'utf8%']
- 比较规则都以与其关联的字符集的名称开头,后面紧跟着该比较规则所应用的语言,如
utf8_polish_ci表示波兰语的比较规则,utf8_general_ci是一种通用的比较规则。名称后缀介绍如下:
| 后缀 |
英文 |
描述 |
| _ai |
accent insensitive |
不区分重音 |
| _as |
accent sensitive |
区分重音 |
| _ci |
case insensitive |
不区分大小写 |
| _cs |
case sensitive |
区分大小写 |
| _bin |
binary |
以二进制的方式比较 |
- 每种字符集都有一个默认的比较规则,是在执行SHOW COLLATION语句返回的结果中Default为YES的比较规则。
各级别的字符集和比较规则
#
服务器级别
#
- mysql提过了两个系统变量来表示服务器级别的字符集和比较规则:
#服务器级别的字符集
SHOW VARIABLES LIKE 'character_set_server'
#服务器级别的比较规则
SHOW VARIABLES LIKE 'collation_server'
[server]
charset_set_server=utf8
collation_server=utf8_general_ci
数据库级别
#
CREATE DATABASE database1
[[DEFAULT] CHARACTER SET utf8]
[[DEFAULT] COLLATE utf8_general_ci]
ALTER DATABASE database1
[[DEFAULT] CHARACTER SET utf8]
[[DEFAULT] COLLATE utf8_general_ci]
表级别
#
- 可以在创建和修改表的时候指定表的字符集和比较规则。
CREATE TABLE table1
...
...
[[DEFALUT] CHARACTER SET utf8]
[COLLATE UTF8_general_ci]
ALTER TABLE table1
[[DEFALUT] CHARACTER SET utf8]
[COLLATE UTF8_general_ci]
列级别
#
CREATE TABLE table1(
column1 varchar(255) [CHARACTER SET utf8] [COLLATE utf8_general_ci]
);
ALTER TABLE table1 MODIFY column1 varchar(255) [CHARACTER SET utf8] [COLLATE utf8_general_ci];
补充
#
- 只修改字符集,则比较规则将修改为修改后的字符集的默认的比较规则。
- 只修改比较规则,则字符集将变为修改后的比较规则对应的字符集。
- 创建或修改列时未显示的指定字符集和比较规则,则该列使用表的字符集和比较规则,如果创建表时未显示的指定字符集和比较规则,则该表默认使用数据库的字符集和比较规则,如果创建数据库时未显示指定字符集和比较规则,则使用mysql服务器的字符集和比较规则。
- mysql5.7及以前的版本,mysql服务器默认的字符集为latin1,mysql8.0后默认字符集为utfmb4。
mysqldump
#
mysqldump可以备份数据库。
mysqldump [options] db_name > file_name
mysqldump [options] --databases db_name ...
- 默认输出到控制台,可通过
>输出到文件。
- 可以直接在后面跟一个数据库名,这样就备份了数据库的表的结构和数据。但不包括建库的语句。
- 可选的option
--databases:备份指定几个数据库。在备份数据库时会加上CREATE DATBASE...和use xxx的语句,--all-databases:备份数据库的所有表,和--databases类似。--add-drop-database:在CREATE DATABASE之前加上DROP DATABASE语句,这个参数与–databases和–all-databases同时使用。--add-drop-table:建表语句之前加上删表语句。--ignore-table:不备份指定的表。--tables: 会覆盖–databases属性mysqldump database1 --tables table1 -u root -p 。--no-data:不备份数据。--force:-f即使在备份期间发生sql异常也继续。--host:-h主机。–user:-u用户。–password:-p密码。–port:-P端口。--xml:输出xml文件。--set-charset:默认启用的参数。
- 一个例子
mysqldump -u root -p --databases test --add-drop-database > test.sql
-
导入sql文件
- 连接上mysql server后使用
source命令导入。
shell>mysql[-u root -p] <dump.sql
shell> mysqladmin create db1 #如果有该数据库就不用建了
shell> mysql [-u root -p] db1 < dump.sql #指定数据库
参考链接:
MySQL :: MySQL 5.7 Reference Manual :: 4.5.4 mysqldump — A Database Backup Program
mysqladmin
#
- mysqladmin可以用来检测服务的配置、创建数据库、关闭mysql服务等。
mysqladmin [options] command [command-arg] [command [command-arg]]
option
#
- –host:指定主机。
- –port(-P):指定端口。
- –user:指定连接用户。
- –version:显示版本信息并退出。
- –wait:如果连接失败,等待并重试。
- –connect-timeout:连接超时的时间。
command
#
- create/drop db_name:创建/删除数据库。
- password “new_password”:修改密码,在windows上确保使用双引号",使用单引号’的话单引号会被识别为密码的一部分。
- shutdown:关闭服务。
- status:显示一个简短的服务状态消息。显示的结果如下:
- Uptime:mysql运行了多少秒。
- Threads:客户端连接的线程数(active)。
- Questions:从服务启动开始客户端查询的数量。
- Slow queries:查询超过
long_query_time秒的数量。
- Opens:服务已经打开了多少张表。
- Flush tables:
flush-*,refresh,reload这些指令服务执行的次数。
- Open tables:当前打开了多少张表。
- version:显示服务的版本信息。
参考链接(官方):
mysqladmin — A MySQL Server Administration Program
参考链接(汉化):
mysqladmin-MySQL 服务器管理程序 | Docs4dev
sql
#
数据类型
#
- 整数数据类型 tinyint(1字节)、smallint(2字节)、mediumint(3字节)、int(4字节)、bigint(8字节)。
- 定点数据类型
decimal(5,2),其中5是精度,表示有效位数;2表示小数点后几位。
- 浮点类型 float(4字节)、double(8字节)。
- 日期和时间类型 DATE(YYYY-MM-DD)、DATETIME(YYYY-MM-DD hh:mm:ss)、TIMESTAMP(范围是UTC1970-01-01 00:00:01-UTC2038-01-19 03:14:07)、TIME(范围-838:59:59-838:59:59)、YEAR(范围是1901-2155)
- 字符串类型 CHAR(长度为声明时的长度,范围0-255)、VARCHAR(可变长度,范围时0-65535)、4种TEXT。
- 字节串类型 BINARY、VARCHAR、四种BLOB。
DATABASE
#
CRATE DATABASE db_name [[DEFAULT] CHARACTER SET [=] utf8];
TABLE
#
#从origin_tb1克隆一个新表(只有结构,没有数据)。
CREATE TABLE new_tb1 LIKE origin_tb1;
#复制origin_tb1表,(结构和数据都复制了)。
CREATE TABLE new_tb1 AS SELECT * FROM origin_tb1;
ALTER
#
#单个alter table可以跟多个修改语句,用逗号隔开
#删除
ALTER TABLE t2 DROP COLUMN c, DROP COLUMN d;
change、modify、alter
#
- change可以重命名列、修改列的定义。配合FIRST或AFTER,可以指定列的位置。
- MODIFY可以修改列的定义,但无法修改它的名字。配合FIRST或AFTER能指定列的名字。
- ALTER只能修改列的默认值。
#将a的名字改为b,修改定义
ALTER TABLE t1 CHANGE a b BIGINT NOT NULL;
#不修改a的名字,只修改定义
ALTER TABLE t1 CHANGE a a BIGINT NOT NULL;
#修改b的定义
ALTER TABLE t1 MODIFY b INT NOT NULL;
#如果只想要修改b的名字而不去修改它的定义,就需要将定义再写一遍
ALTER TABLE t1 CHANGE b a INT NOT NULL;
#除了如PRIMARY KEY或UNIQUE属性,其他的如DEFAULT COMMENT等需要在修改时带上,否则修改后的列是没有这些属性。
#使用CHANGE或MODIFY,myslq会尝试将列中数据转化未新的类型。
#当使用CHANGE修改列名后,使用了该列的VIEW需要修改。
#ALTER TABLE xxx ALTER ...SET DEFAULT xxx或ALTER ... DROP DEFAULT。如果旧的默认值被删除而列不可以为NULL,mysql将为其分配默认值(数字类型默认为0,如果指定了AUTO_INCREMENT,默认值是序列中的下一个值,对于EMUM,默认值为第一个枚举值,对于其他字符串类型,默认值为空字符串)。
ALTER TABLE `service`.`email_relation` RENAME TO `service`.`relation` ;
ALTER TABLE `service`.`relation` CHANGE COLUMN `email` `mail` VARCHAR(64) NULL DEFAULT NULL ;
SHOW
#
#显示属性
SHOW COLUMNS FROM MYSQL.USER;
#显示建库语句,例:
SHOW CREATE DATABASE MYSQL;
#显示建表语句,例:
SHOW CREATE TABLE MYSQL.USER;
#显示创建该用户的语句
SHOW CREATE USER root;
#显示分配个某用户的特权
SHOW GRANTS [FOR user];
show grants for 'joe'@'home.example.com'