2020-10-20
- 模式定义:将抽象与实现分离,使它们都可以独立地变化。
- 应用场景:两个非常强的变化维度。
案例
#
-
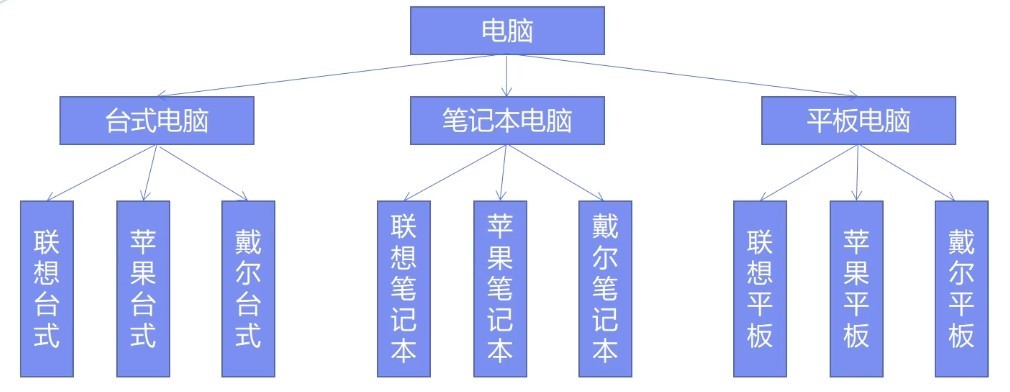
分析一下,首先会创建1个电脑类,然后创建3个电脑的子类(即电脑的类型),再创建3x3个子类。假设有n种电脑类型,m种电脑品牌,那么产生的类的数量为1+n+nxm。
-
如果再加一个电脑品牌acer,则需要再添加三个类,即acer台式机、acer笔记本、acer平板。显然这种方式产生的类的数量非常多。
-
此外,这个实现违背了单一职责原则,类中出现了两个变化(电脑类型和品牌)。
-
解决办法:将类型写成一个抽象类,将品牌写成一个抽象类。通过一个"桥"将他们联系起来。
//品牌类
interface Brand{
void info();
}
class Lenovo implements Brand{
public void info(){
//...
}
}
class Apple implements Brand{
public void info(){
//...
}
}
class Dell implements Brand{
public void info(){
//...
}
}
//电脑类
abstract class Computer{
//通过类组合来替代类继承
protected Brand brand;
public Computer(Brand brand){this.brand=brand;}
abstract void info();
}
class Desktop extends Computer{
public Desktop(Brand brand){super(brand);}
public void info(){
//...
}
}
class Laptop extends Computer{
public Laptop(Brand brand){super(brand);}
public void info(){
//...
}
}
class Pad extends Computer{
public Pad(Brand brand){super(brand);}
public void info(){
//...
}
}
- 通过上面的修改,类的数量变成了1+n+m。
- 在这里我理解的抽象是Brand,实现指的是Computer和Computer的子类。
2020-10-08
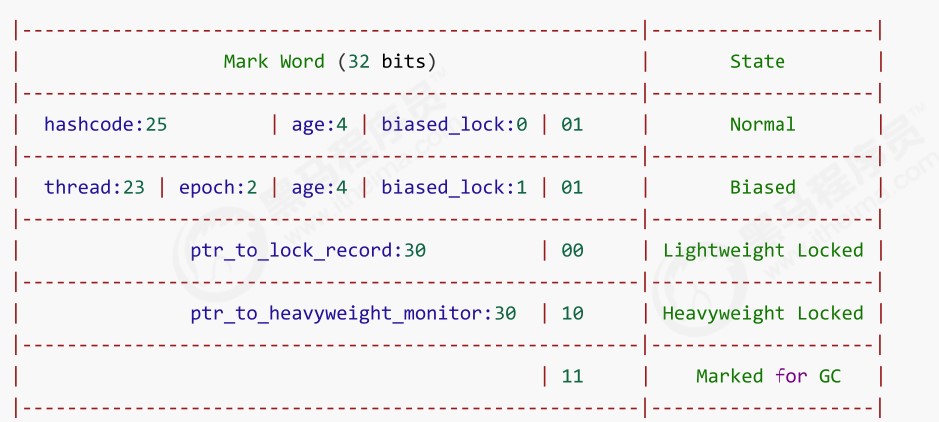
public enum State {
// 线程刚被创建,但是还没调用start方法
NEW,
/**
* 该状态的线程在jvm中是执行状态,但是在操作系统中可能是在等待其他的资源。
* 此状态涵盖了操作系统中的 运行态、就绪态、阻塞态
*/
RUNNABLE,
/**
* 此状态的线程会等待一个monitor lock。
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling Object.wait
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* 以下方法可使线程进入此状态:
* Object.wait with no timeout
* Thread.join with no timeout
* LockSupport.park
* 该状态的线程会等待其他线程通过特定的动作唤醒。
*/
WAITING,
/**
* Thread state for a waiting thread with a specified(特定的) waiting time.
* 以下方法可使线程进入此状态:
* Thread.sleep
* Object.wait with timeout
* Thread.join with timeout
* LockSupport.parkNanos
* LockSupport.parkUntil
*/
TIMED_WAITING,
// 线程已经完成了执行,终止了的状态。
TERMINATED;
}
2020-10-08
Thread方法
#
-
sleep:让当前线程休眠n毫秒,休眠时让出cpu的时间片给其他线程。
-
join:等待某个线程运行结束。
-
yield:提示线程调度器让出当前线程对 CPU的使用。
-
interrupt():打断线程,可能会产生打断标记(看下面的介绍)。
- 可以使用isInterrupted()判断线程是否被打断。
- 如果线程正在sleep、wait、join会导致被打断的线程抛出InterruptedException,并清除打断标记。
- 如果打断正在运行的线程,则会设置打断标记。
- interrupted()方法能返回打断标记的状态,并将打断标记设置为假。
同步
#
- 同步:需要等待结果返回,才能继续运行就是同步。
- 异步:不需要等待结果返回,就能继续运行就是异步。
常见线程安全类
#
String Integer StringBuffer Random Vector Hashtable java.util.concurrent
2020-10-06
- 在调用wait方法时,线程必须要持有被调用对象的锁,当调用wait方法之后,线程就会释放掉该对象的锁。
- 在调用Thread类的sleep方法时,线程是不会释放掉对象的锁的。
- 当调用wait方法时,首先要确保调用了wait方法的线程已经持有了对象的锁。
- 当调用了wait后,该线程就会释放掉这个对象的锁,然后进入等待状态,该线程进入对象的等待集合中(wait set)。
- 当线程调用了wait后进入到等待状态时,它就等待其他线程调用相同对象的notify和notifyAll方法来使得自己被唤醒。
- 调用wait方法的代码片段需要放在一个synchronized块或者被synchronized修饰的方法中。
- 当调用了对象的notify方法时,它会随机唤醒该对象等待集合中(wait set)的任意一个线程,当某个线程被唤醒后,它就会与其他线程一同竞争对象的锁。
- 当调用对象的notifyAll方法时,它会唤醒该对象等待集合中(wait set)中所有的线程,这些线程被唤醒后,又会开始竞争对象的锁。
- 某一时刻,只有唯一的一个线程拥有对象的锁。
具体案例
#
Demon对象有一个int类型的属性counter,该值初始为0;
创建四个线程,两个线程对该值增1,两个线程对该值减1;
输出counter每次变化后的结果,要求输出结果为1010101010…。
包含counter的Demon类
#
//该对象提供加1和减1的操作
class Demon{
//counter
private int counter=0;
//对方法加锁,当一个线程要调用该方法时,需要先获取该对象的锁
public synchronized void inc(){//counter加1
//此处必须使用while而不是if,防止被其他不相关的线程唤醒
while(counter!=0){
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
counter++;
System.out.print(counter);
/*此处必须使用notifyAll,notify会从等待队列中
随机选择一个线程唤醒,可能会导致程序一直阻塞*/
notifyAll();
}
//counter减1
public synchronized void dec(){
while(counter!=1){
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
counter--;
System.out.print(counter);
notifyAll();
}
}
关键代码如上,剩余的代码也都比较简单,就省略了。如果你需要所有代码,可以通过ctrl+u查看网页源代码,并使用ctrl+f快捷键搜索"黑魔仙变身"即可找到完整代码。手机需要使用能查看网页源代码的浏览器,如via等。
2020-09-30
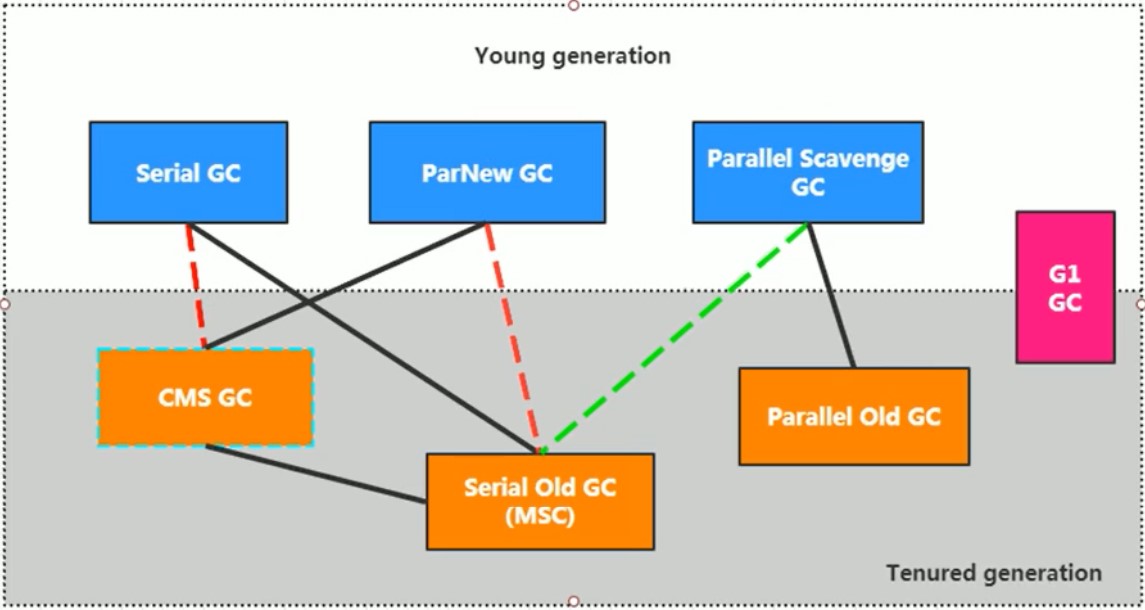
-XX:+PrintCommandLineFlags:查看命令行参数(可打印出使用的是哪个垃圾回收器)。
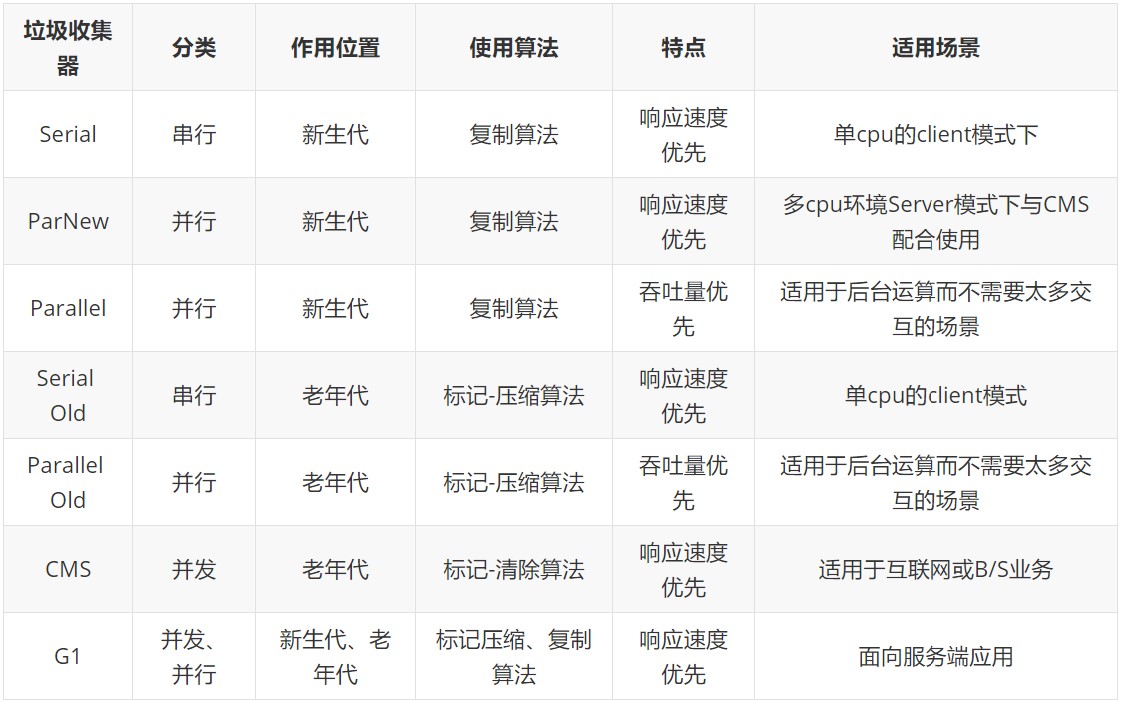
Serial回收器:串行回收
#
-
Client模式下默认的新生代垃圾收集器。
-
Serial收集器采用复制算法、串行回收和“Stop-The-World”机制的方式执行内存回收。
-
Serial Old-对应的老年代垃圾收集器,同样采用串行回收和“Stop-The-World”机制,只不过内存回收算法使用的是标记-压缩算法。
- Serial Old是Client模式下默认的老年代的垃圾收集器。
- Serial Old在Server模式下主要有两个用途:①与新生代的Parallel Scavenge配合使用;②作为老年代CMS收集器的后备垃圾收集方案。
-
这个收集器是一个单线程的收集器,在它进行垃圾收集时,必须停掉其他所有的工作线程,直到它收集结束。
-
-XX:+UseSerialGC:指定新生代Serial,老年代Serial Old GC。
ParNew回收器:并行回收
#
Parallel Scavenge回收器:吞吐量优先
#
-
同样采用并行回收、复制算法、STW机制。
-
Parallel Scavenge收集器的目标是达到一个可控的吞吐量,它也被称为吞吐量优先的垃圾收集器。
-
自适应调节机制也是Parallel Scavenge与ParNew的一个重要区别。
-
高吞吐量可以高效的利用cpu时间,尽快的完成程序的运算任务。主要用于在后台运算而不需要太多交互的任务。
-
应用场景:执行批量处理、订单处理、工资支付、科学计算的应用程序。
-
Parallel Old:老年代垃圾收集器,采用标记-压缩算法、并行回收、STW机制。
-
-XX:+UseParallelGC:手动指定年轻代使用Parallel;-XX:+UserParallelOldGC:手动指定老年代。这两个参数,当指定一个,另一个也会被开启。
-
-XX:ParallelGCThreads:设置年轻代并行的线程数。
-
-XX:+UseAdaptiveSizePolicy:设置Parallel收集器具有自适应调节策列。
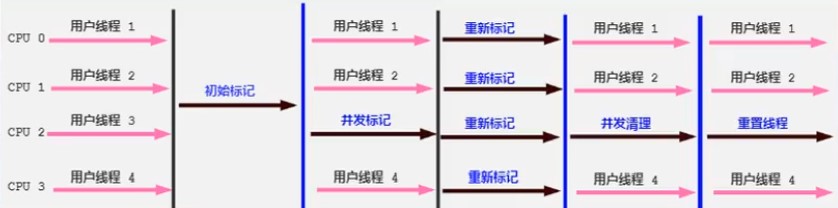
CMS回收器:低延迟(Concurrent-Mark-Sweep)
#
-
由于在垃圾收集阶段用户线程仍在执行,所以在CMS回收过程中,要保证应用程序线程有足够的内存可用。因此,CMS收集器不能像别的收集器一样等到老年代几乎完全填满了才进行垃圾回收,而是在堆内存达到某一个阈值时,便开始进行回收。当CMS运行期间,内存无法满足程序要求,这时虚拟机会启用预备方案:临时使用Serial Old进行垃圾回收。
-
CMS采用标记-清除算法,只能采用空闲列表进行内存分配。
-
优点:低延迟,并发收集。
-
缺点:产生内存碎片;对cpu资源非常敏感,因为占用了一部分线程,会导致吞吐量降低;无法处理浮动垃圾(并发标记阶段如果产生新的垃圾,cms无法对这些垃圾进行标记,会导致这些垃圾无法及时的被回收)。
-
-XX:+UseConcMarkSweepGC:手动指定使用CMS收集器。
G1回收器:区域分代化
#
2020-09-29
System.gc()的理解
#
- 在默认情况下,通过System.gc()或者Runtime.getRuntime().gc()的调用会显示触发Full GC,但是该方法可能不是立刻就执行。
内存溢出
#
- 产生原因:没有空闲内存,并且垃圾收集器也无法提供更多内存。
内存泄漏
#
- 严格定义:对象不再被程序使用了,但是GC又不能回收他们的情况(仍然存在引用链)。
- 宽泛定义:一些不太好的实践会导致对象的生命周期变得很长,甚至导致OOM,也叫宽泛意义上的内存泄漏。
安全点
#
- 程序执行时并非在所有的地方都能停下来开始GC,只有在特定的位置才能停顿下来开始GC,这些位置称为“安全点”(safepoint)。
- 如何在GC发生时,检测所有的程序都跑到最近的安全点停顿下来了呢 –> 主动式中断:设置一个中断标志,各个线程运行到safe point的时候主动轮询这个标志,如果中断标志为真,则将自己进行中断挂起。
安全区域
#
- 指在一段代码片段中,对象的引用关系不会发生变化,在这个区域中的任何位置开始GC都是安全的。
- 可以应对处于sleep或者blocked状态的线程,这时候线程无法响应jvm的中断请求,“走”到安全点去中断挂起。
- 当程序运行到safe region的代码时,首先标识已经进入了safe region,如果这段时间发生了gc,jvm会忽略标识为safe region状态的线程。
- 当线程即将离开safe region时,会检测jvm是否已经完成了gc,如果完成了,则继续运行,否则线程必须等待直到收到可以安全离开safe region的信号为止。
引用
#
//声明强引用
Object obj=new Object();
//声明软引用
SoftReference<Object> sf=new SoftReference<Object>(new Object());
//声明弱引用
WeakReference<Object> wr=new WeakReference<Object>(new Object());
//虚引用
Object obj=new Object();
ReferenceQueue<Object> rq=new ReferenceQueue<>();
PhantomReference<Object> pr=new PhantomReference<>(obj,rq);
评估性能指标
#
- 吞吐量:运行用户代码时间占总运行时间的比例。
- 垃圾收集开销:吞吐量的补数,垃圾收集所用时间与总运行时间的比例。
- 暂停时间:执行垃圾收集时,程序的工作线程被暂停的时间。
- 收集频率:相对于应用程序的执行,收集操作发生的频率。
- 内存占用:Java堆区所占的内存大小。
- 快速:一个对象从诞生到被回收所经历的时间。